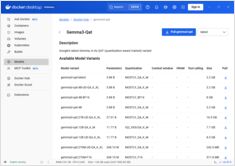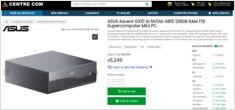
تسعير DGX Spark AU: من 6249 إلى 7999 دولارًا في المتاجر الكبرى
الأسعار الفعلية بالدولار الأسترالي من البائعين الأستراليين الآن
ال NVIDIA DGX Spark (GB10 Grace Blackwell) هي الآن متوفرة في أستراليا في متاجر الكمبيوتر الرئيسية مع مخزون محلي. إذا كنت قد كنت تتابع أسعار وتوافر DGX Spark عالمياً فإنك ستكون مهتماً بمعرفة أن الأسعار في أستراليا تتراوح بين 6249 إلى 7999 دولار أسترالي حسب تكوين التخزين والمتجر.