

LLM Wiki-onderhoud: Drift, tegenstrijdigheden en evaluatie
Houd samengestelde kennis betrouwbaar
Een LLM Wiki faalt wanneer oude feiten aannemelijk blijven, tegenstrijdigheden worden gepolijst en gegenereerde samenvattingen afwijken van hun bronnen.
Houd samengestelde kennis betrouwbaar
Een LLM Wiki faalt wanneer oude feiten aannemelijk blijven, tegenstrijdigheden worden gepolijst en gegenereerde samenvattingen afwijken van hun bronnen.

Privésynchronisatie voor lokale kennis.
Syncthing houdt bestanden gesynchroniseerd tussen apparaten die jij beheert, waardoor het een van de meest praktische tools is voor een zelfgehoste kennisinfrastructuur die cloud-lock-in vermijdt.

Voorkom cascadefouten in Go-microservices.
Een circuitbreker voorkomt dat je Go-service een falende afhankelijkheid blijft bombarderen, waardoor cascaderende falingen worden voorkomen die goroutines, sockets en geheugen consumeren totdat het hele systeem instort.

Kies de juiste containerworkflow.
Docker Compose en Podman Quadlet lossen overlappende problemen op, maar komen uit verschillende ontwerpcentra. De keuze tussen hen hangt af van of je denkt in applicatiestacks of Linux-services.

Vergelijking van AI-GPU’s van drie leveranciers
Het landschap van AI-hardware is in 2026 aanzienlijk verschoven, waarbij NVIDIA, AMD en Intel allemaal concurreren om ontwikkelaars die GPUs nodig hebben die geschikt zijn voor het lokaal draaien van grote taalmodellen (LLMs) en AI-inferentiewerklasten.

Headless Hermes-server met toegang tot de remote desktop
Het uitvoeren van de Hermes Agent op een headless server terwijl je vanaf een desktopclient op een andere machine verbinding maakt, vereist twee serverprocessen en één clientverbinding.

Procesdiepte versus draagbaarheid, niet het beste gereedschap.
Ontwikkelaars die in 2026 Spec-Driven Development-opstellingen vergelijken, vragen zich meestal niet af welk model het slimst is. Ze vragen zich af welke workflow een AI-agent consistent houdt zonder hen te begraven onder bureaucratie.
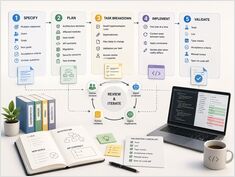
Vijf fasen van intentie tot geverifieerde code.
Spec-gedreven ontwikkeling werkt wanneer de specificatie een workflow is, en geen document dat je na de kickoff weglegt. Het doel is niet het produceren van een uitgebreid productvereisten document.
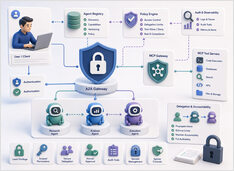
Protocolbeveiliging bepaalt wie mag handelen, niet het model.
Promptinjectie krijgt de meeste aandacht op het gebied van beveiliging in LLM-systemen, en dat is terecht, maar het is niet het enige probleem zodra agents tools gaan aanroepen en werk delegeren aan andere agents.
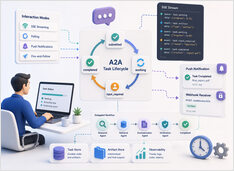
Langlopende A2A-taaken overleven chatsessies.
De meeste AI-agentdemonstraties gedragen zich nog steeds als chat-completies met extra stappen: je stuurt een prompt, wacht enkele seconden en ontvangt een antwoord in één reactie.
Docker Compose bij het opstarten, beheerd door systemd.
Docker Compose op een Linux-server moet bij het opstarten starten, tijdens het afsluiten netjes stoppen en herstarts overleven zonder handmatige ingrepen.

Kies het juiste Docker-installatiepad op Ubuntu.
Het installeren van Docker op Ubuntu zou eenvoudig moeten zijn, maar in de praktijk concurreren verschillende Docker-achtige opties om dezelfde commandonamen, elk met verschillende pakketindeling, upgrade-gedrag en veiligheidsimplicaties.

Ubuntu APT repareren zonder raden.
Apt-fouten komen veel voor op Ubuntu-systemen die al langere tijd draaien, en ze treden meestal op na een versie-upgrade, een wijziging in een extern repository, een verwijderde PPA, een handmatig geïnstalleerde .deb-bestand of een onderbroken pakketinstallatie.

Snellere LLM-inferentie zonder kwaliteitsverlies – een praktische handleiding
Een model van 70B (70 miljard parameters) genereert één token per forward pass, en bij elke pass worden de gewichten opnieuw van het VRAM geladen, wordt de attention berekend over de context en wordt het gehege synchroniseerd. Tussen tokens zit de GPU inactief terwijl hij wacht tot sequentiële afhankelijkheden zijn opgelost.

40% van multi-agentpilots faalt. Hier is hoe je het juiste orchestratiepatroon kiest – en de patronen vermijdt die falen.
Single-agent AI-systemen bereikten hun hoogtepunt in 2025 — u gaf één LLM een prompt, enkele tools en een doel, en het presteerde redelijk goed bij begrenste taken.

Schrijf het gebeurtenis met de gegevens. Splits ze nooit.
Twee schrijfacties die samen zouden moeten slagen, zullen uiteindelijk afzonderlijk falen.
Uw orderservice slaat de bestelling op in de database en publiceert vervolgens een order.created-gebeurtenis naar een message broker.
Ontvang nieuwe berichten over systemen, infrastructuur en AI-engineering.