
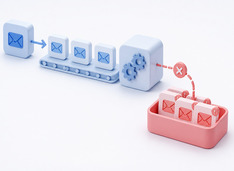
デッドレターキュー:分散システムにおけるポイズンメッセージの処理
メッセージのポイズニングによるキューのブロックを防止する
デッドレターキュー(DLQ)は、コンシューマーが処理できないメッセージを捕捉する安全ネットです。これにより、1つの破損したペイロードがキュー内のその後のすべてのメッセージをブロックしたり、静かにドロップしたりすることが防がれます。
メッセージのポイズニングによるキューのブロックを防止する
デッドレターキュー(DLQ)は、コンシューマーが処理できないメッセージを捕捉する安全ネットです。これにより、1つの破損したペイロードがキュー内のその後のすべてのメッセージをブロックしたり、静かにドロップしたりすることが防がれます。

コンパイルされた知識の信頼性を確保する
LLMウィキは、古い事実が依然として妥当に見えるようになり、矛盾が磨き上げられ、生成された要約が元々の情報源から逸脱した際に失敗します。

ローカルナレッジのためのプライベート同期
Syncthingは、あなたが管理するデバイス間でファイルを同期し続けるため、クラウドロックインを回避する自己ホスト型ナレッジインフラにおいて最も実用的なツールの一つとなっています。

Goマイクロサービスにおけるカスケード障害を防止する
サーキットブレーカーは、Goのサービスが故障した依存先に対して過剰な呼び出しを行うことを防ぎ、goroutine、ソケット、メモリを消費してシステム全体が崩壊するまでカスケード障害(連鎖障害)を引き起こすのを防ぎます。

適切なコンテナワークフローを選択してください。
Docker ComposeとPodman Quadletは重複する問題を解決しますが、異なる設計理念から来ています。どちらを選ぶかは、アプリケーションスタックとして考えるか、Linuxサービスとして考えるかに依存します。

3社によるAI GPUの比較
2026年、AIハードウェアの状況は大きく変化しました。NVIDIA、AMD、Intelの各社が、ローカル環境で大型言語モデル(LLM)やAI推論ワークロードを実行できるGPUを必要とする開発者を獲得するため、激しい競争を繰り広げています。

リモートデスクトップアクセスに対応したヘッドレスHermesサーバー
ヘッドレスサーバーで Hermes エージェントを実行し、別のマシンのデスクトップクライアントから接続するには、2つのサーバープロセスと1つのクライアント接続が必要です。

プロセスの深さとポータビリティを比較し、最適なツールではありません。
2026年にSpec-Driven Development(SDD)のセットアップを比較する開発者は、どのモデルが最も賢いかを問うことは通常ありません。彼らが問うのは、AIエージェントを整合的に保ちつつ、過度な儀式(ceremony)に埋もれさせないワークフローは何かということです。
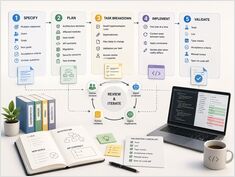
意図から検証済みのコードへ:5つのフェーズ
仕様駆動型開発(SDD)は、仕様がドキュメントとしてキックオフ後に棚卸しされるものではなく、ワークフローそのものであるときに機能します。目的は、大規模な製品要件定義ドキュメントを作成することではありません。
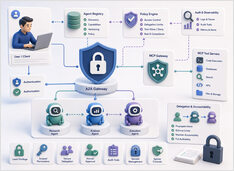
プロトコルセキュリティはモデルではなく、誰が実行できるか(誰が操作を行えるか)を定義するものです。
LLMシステムにおけるセキュリティの関心は、プロンプトインジェクションに最も集中していますが、それは確かに注目を集めるべきものです。しかし、エージェントがツールを呼び出し、他のエージェントに作業を委任し始めると、それは問題の一部に過ぎなくなります。
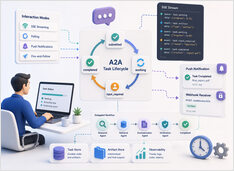
長期実行されるA2Aタスクは、チャットセッションの終了後も継続して実行されます。
ほとんどのAIエージェントのデモは、追加のステップを伴うチャット補完のように振る舞います。プロンプトを送信し、数秒待ってから、1つのレスポンスとして回答を受け取ります。
systemd によって管理される起動時の Docker Compose
Linux サーバー上の Docker Compose は、ブート時に起動し、シャットダウン時にクリーンに停止し、手動介入なしで再起動に耐えられるべきです。

Ubuntuで適切なDockerのインストールパスを選択してください。
Ubuntu に Docker をインストールするのは本来シンプルであるはずですが、実際には複数の「Docker 関連」の選択肢が同じコマンド名を巡って競合しており、それぞれ異なるパッケージ構成、アップグレード動作、セキュリティへの影響を持っています。

推測不要でUbuntuのAPTを修復する
長期間稼働している Ubuntu マシンでは、APT のエラーはよく発生します。これらは通常、リリースアップグレード、サードパーティリポジトリの変更、PPA の削除、手動インストールされた .deb ファイル、または中断されたパッケージインストールの後に現れます。

質の低下なしでLLM推論を高速化する方法 — 実践ガイド
70Bパラメータのモデルは1回のフォワードパスで1つのトークンを生成し、各パスではVRAMから重みを読み込み、コンテキスト全体でアテンションを計算し、メモリを同期します。トークンの間では、逐次依存関係が解決されるのを待つ間、GPUはアイドル状態になります。

マルチエージェントパイロットの40%が失敗に終わる。適切なオーケストレーションパターンを選択し、破綻するパターンを回避する方法を紹介する。
2025年、単一エージェントのAIシステムは最盛期を迎えました。一つのLLMにプロンプト、いくつかのツール、そして目標を与えるだけで、限定されたタスクではそれなりの成果を上げることができました。
システム、インフラ、AIエンジニアリングの新記事をお届けします。