
واجهة Open WebUI: واجهة LLM مُستضافة ذاتيًا
بديل لـ ChatGPT مضيف ذاتي للنماذج الكبيرة المحلية
Open WebUI هي واجهة ويب قوية وقابلة للتوسيع ومُزودة بجميع الميزات اللازمة لتفاعل مع النماذج الكبيرة للغات.
بديل لـ ChatGPT مضيف ذاتي للنماذج الكبيرة المحلية
Open WebUI هي واجهة ويب قوية وقابلة للتوسيع ومُزودة بجميع الميزات اللازمة لتفاعل مع النماذج الكبيرة للغات.
استنتاج نموذج LLM السريع باستخدام واجهة برمجة التطبيقات الخاصة بـ OpenAI
vLLM هو محرك استنتاج وتقديم ذا كفاءة عالية في الذاكرة لمحركات النماذج الكبيرة (LLMs) تم تطويره من قبل مختبر سكاي كومبيتينغ في جامعة كاليفورنيا بيركلي.
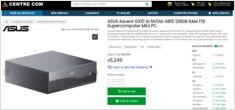
الأسعار الفعلية بالدولار الأسترالي من البائعين الأستراليين الآن
ال NVIDIA DGX Spark (GB10 Grace Blackwell) هي الآن متوفرة في أستراليا في متاجر الكمبيوتر الرئيسية مع مخزون محلي. إذا كنت قد كنت تتابع أسعار وتوافر DGX Spark عالمياً فإنك ستكون مهتماً بمعرفة أن الأسعار في أستراليا تتراوح بين 6249 إلى 7999 دولار أسترالي حسب تكوين التخزين والمتجر.

دليل تقني للكشف عن المحتوى المُنتج بواسطة الذكاء الاصطناعي
الانتشار المفرط للمحتوى المُنتَج بواسطة الذكاء الاصطناعي أدى إلى تحدي جديد: تمييز الكتابة البشرية الحقيقية من “AI slop” - نصوص صناعية منخفضة الجودة، وتم إنتاجها بكميات كبيرة.

اختبار Cognee مع نماذج LLM المحلية - نتائج حقيقية
Cognee هي إطار عمل بلغة Python لبناء مخططات المعرفة من الوثائق باستخدام LLMs. لكن هل يعمل مع النماذج المضيفة محليًا؟

مخرجات نموذج LLM الآمن من الناحية النوعية باستخدام BAML والدروسية
عند العمل مع نماذج لغات كبيرة في الإنتاج، فإن الحصول على مخرجات منظمة وآمنة من حيث النوع أمر حيوي. تتناول إطارات شائعة مثل BAML و Instructor نهجًا مختلفًا لحل هذه المشكلة.

آراء حول نماذج LLM للنسخة المثبتة محليًا من Cognee
اختيار أفضل نموذج LLM لـ Cognee يتطلب موازنة جودة بناء الرسوم البيانية، معدلات التخيل، والقيود المادية. Cognee تتفوق مع النماذج الكبيرة ذات التخيل المنخفض (32B+) عبر Ollama ولكن الخيارات المتوسطة تعمل للاعدادات الخفيفة.

أنشئ وكلاء بحث ذكاء اصطناعي باستخدام بايثون وOllama
أصبحت مكتبة Ollama لـ Python تحتوي الآن على إمكانيات بحث Ollama على الويب الأصلية. باستخدام بضع سطور من الكود فقط، يمكنك تعزيز نماذج LLM المحلية ببيانات حقيقية من الإنترنت، مما يقلل من الهلوسات ويزيد من الدقة.

اختر قاعدة بيانات المتجهات المناسبة لstack RAG الخاص بك
اختيار خزن المتجهات المناسب يمكن أن يحدد نجاح أو فشل تطبيق RAG من حيث الأداء، التكلفة، والقدرة على التوسع. تغطي هذه المقارنة الشاملة خيارات أكثر شيوعًا في عامي 2024-2025.

أنشئ وكلاء بحث ذكاء اصطناعي باستخدام Go وOllama
واجهة بحث الويب في Ollama تتيح لك تحسين نماذج LLM المحلية بمعلومات الويب في الوقت الفعلي. توضح هذه المقالة لك كيفية تنفيذ قدرات البحث عبر الويب في Go، من مكالمات API بسيطة إلى وكلاء البحث المتكاملين.

استخدم 12+ أداة لمقارنة نشر نماذج LLM المحلية بشكل محترف
النشر المحلي للنماذج الكبيرة أصبح أكثر شيوعًا مع تطلع المطورين والمنظمات إلى خصوصية محسنة وتقليل التأخير وزيادة السيطرة على بنية تحتية الذكاء الاصطناعي الخاصة بهم.

أنشئ أنظمة أنابيب AI/ML قوية باستخدام خدمات Go الصغيرة
مع تزايد تعقيد أعباء الذكاء الاصطناعي والتعلم الآلي، أصبحت الحاجة إلى أنظمة تنسيق قوية أكثر إلحاحًا.
بسبب بساطتها و أدائها و قدرتها على التعامل مع المهام المتزامنة، تصبح لغة Go خيارًا مثاليًا لبناء طبقة التنسيق الخاصة ب_PIPELINES_ التعلم الآلي، حتى عندما تكون النماذج نفسها مكتوبة بلغة Python.

دمج النصوص والصور والصوت في مساحات تضمين مشتركة
الإمبددنجات المتقاطعة تمثل تقدمًا كبيرًا في الذكاء الاصطناعي، حيث تتيح فهمًا وتنقيحًا عبر أنواع البيانات المختلفة داخل مساحة تمثيل موحدة.

قم بتشغيل الذكاء الاصطناعي المؤسسي على معدات ميسرة بأسعار معقولة باستخدام نماذج مفتوحة المصدر
الديموقراطية في الذكاء الاصطناعي هنا. مع نماذج LLM المفتوحة المصدر مثل Llama 3، وMixtral، وQwen الآن تنافس النماذج الخاصة، يمكن للمجموعات بناء بنية تحتية قوية للذكاء الاصطناعي باستخدام معدات الاستهلاك - مما يقلل التكاليف مع الحفاظ على التحكم الكامل في خصوصية البيانات والنشر.

LongRAG، Self-RAG، GraphRAG - تقنيات الجيل التالي
الإيجاد المعزز بالاسترجاع (RAG) قد تطور إلى ما يتجاوز البحث المبسط بناءً على التشابه بين المتجهات. LongRAG، وSelf-RAG، وGraphRAG تمثل أحدث ما توصل إليه في هذه القدرات.

تسريع FLUX.1-dev باستخدام كمّ量化 GGUF
FLUX.1-dev هو نموذج قوي لتحويل النص إلى صورة ينتج نتائج مذهلة، ولكن متطلباته من الذاكرة البالغة 24 جيجابايت أو أكثر تجعله تحديًا لتشغيله على العديد من الأنظمة. تكميم GGUF لـ FLUX.1-dev يقدم حلًا، حيث يقلل من استخدام الذاكرة بنسبة تصل إلى 50% مع الحفاظ على جودة الصورة الممتازة.