

डॉकर मॉडल रनर: कॉन्टेक्स्ट साइज़ कॉन्फ़िग गाइड
डॉकर मॉडल रनर में कॉन्टेक्स्ट साइज़ को कॉन्फ़िगर करें, साथ ही कार्यारंभिक समाधानों का उपयोग करें
डॉकर मॉडल रनर में कॉन्टेक्स्ट साइज कॉन्फ़िगर करने का कॉन्फ़िगरेशन अधिक जटिल है जितना होना चाहिए।
डॉकर मॉडल रनर में कॉन्टेक्स्ट साइज़ को कॉन्फ़िगर करें, साथ ही कार्यारंभिक समाधानों का उपयोग करें
डॉकर मॉडल रनर में कॉन्टेक्स्ट साइज कॉन्फ़िगर करने का कॉन्फ़िगरेशन अधिक जटिल है जितना होना चाहिए।

इमेजों को टेक्स्ट निर्देशों के साथ बढ़ाने के लिए AI मॉडल
ब्लैक फॉरेस्ट लैब्स ने FLUX.1-Kontext-dev जारी किया है, एक उन्नत इमेज-टू-इमेज एआई मॉडल जो टेक्स्ट निर्देशों का उपयोग करके मौजूदा इमेजों को बढ़ाता है।

डॉकर मॉडल रनर के लिए एनवीडिया CUDA समर्थन के साथ GPU त्वरण सक्षम करें
डॉकर मॉडल रनर डॉकर का आधिकारिक टूल है जो स्थानीय रूप से AI मॉडल चलाने के लिए है, लेकिन डॉकर मॉडल रनर में NVidia GPU त्वरक सक्षम करना के लिए विशेष कॉन्फ़िगरेशन की आवश्यकता होती है।

बुद्धिमान टोकन अनुकूलन के साथ LLM लागत को 80% तक कम करें
टोकन अनुकूलन वह महत्वपूर्ण कौशल है जो लागत-प्रभावी एलएलएम अनुप्रयोगों को बजट-खर्च करने वाले प्रयोगों से अलग करता है।

GPT-OSS 120b तीन AI प्लेटफॉर्म पर बेंचमार्क

पाइथन उदाहरणों के साथ एआई सहायक के लिए MCP सर्वर बनाएं
मॉडल कॉन्टेक्स्ट प्रोटोकॉल (MCP) बाहरी डेटा स्रोतों और टूल्स के साथ AI सहायकों के इंटरैक्शन के तरीके को क्रांतिकारी बना रहा है। इस गाइड में, हम Python में MCP सर्वर बनाना के बारे में जानेंगे, जिसमें वेब सर्च और स्क्रैपिंग क्षमताओं पर फोकस किए गए उदाहरण शामिल हैं।

एचटीएमएल को साफ़ और एलएलएम-तैयार मार्कडाउन में बदलने के लिए पाइथन
HTML को Markdown में बदलना आधुनिक विकास कार्यप्रवाहों में एक मूलभूत कार्य है, विशेष रूप से जब वेब सामग्री को बड़े भाषा मॉडल (LLMs), दस्तावेज़ीकरण प्रणालियों, या स्टैटिक साइट जनरेटर जैसे ह्यूगो के लिए तैयार किया जाता है।
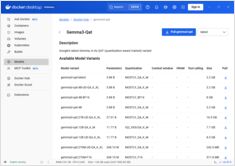
डॉकर मॉडल रनर कमांड्स के लिए त्वरित संदर्भ
डॉकर मॉडल रनर (डीएमआर) डॉकर का आधिकारिक समाधान है जो स्थानीय रूप से एआई मॉडल चलाने के लिए है, जो अप्रैल 2025 में पेश किया गया था। यह चीटशीट सभी आवश्यक कमांड्स, कॉन्फ़िगरेशन, और बेस्ट प्रैक्टिसेस के लिए एक तेज़ संदर्भ प्रदान करता है।
डॉकर मॉडल रनर और ओल्लामा को स्थानीय एलएलएम के लिए तुलना करें
स्थानीय रूप से बड़े भाषा मॉडल (LLMs) चलाना अब गोपनीयता, लागत नियंत्रण, और ऑफ़लाइन क्षमताओं के लिए increasingly popular हो गया है। अप्रैल 2025 में, जब Docker ने Docker Model Runner (DMR) पेश किया, तो परिदृश्य महत्वपूर्ण रूप से बदल गया, जो AI मॉडल डिप्लॉयमेंट के लिए इसका आधिकारिक समाधान है।

खास चिप्स AI इन्फरेंस को तेज़ और सस्ता बना रहे हैं
भविष्य की AI केवल अधिक बुद्धिमान मॉडल्स के बारे में नहीं है - यह अधिक बुद्धिमान सिलिकॉन के बारे में है। LLM इन्फरेंस के लिए विशेषीकृत हार्डवेयर एक क्रांति को चलाने में मदद कर रहा है जो बिटकॉइन माइनिंग के ASICs की ओर शिफ्ट के समान है।

उपलब्धता, छह देशों में वास्तविक रिटेल मूल्य, और मैक स्टूडियो के साथ तुलना।
NVIDIA DGX Spark वास्तविक है, बिक्री 15 अक्टूबर, 2025 से, और यह CUDA डेवलपर्स के लिए बनाया गया है जो स्थानीय LLM कार्य के लिए एक एकीकृत NVIDIA AI स्टैक की आवश्यकता रखते हैं। यूएस एमएसआरपी $3,999; UK/DE/JP रिटेल अधिक है VAT और चैनल के कारण। AUD/KRW सार्वजनिक स्टिकर मूल्य अभी तक व्यापक रूप से पोस्ट नहीं किए गए हैं।

इन दो मॉडलों की गति, पैरामीटर्स और प्रदर्शन का तुलनात्मक अध्ययन
यहाँ Qwen3:30b और GPT-OSS:20b के बीच तुलना है, जो निर्देश पालन और प्रदर्शन पैरामीटर्स, स्पेसिफिकेशन्स और गति पर केंद्रित है:

+ सोचने वाले LLMs का उपयोग करने के विशिष्ट उदाहरण
इस पोस्ट में, हम दो तरीकों का पता लगाएंगे जिससे आप अपने Python एप्लिकेशन को Ollama से कनेक्ट कर सकते हैं: 1. HTTP REST API के माध्यम से; 2. अधिकृत Ollama Python लाइब्रेरी के माध्यम से।

बहुत अच्छा नहीं।
Ollama के GPT-OSS मॉडल्स में संरचित आउटपुट को हैंडल करने में बार-बार समस्याएं आती हैं, विशेष रूप से जब उन्हें LangChain, OpenAI SDK, vllm जैसे फ्रेमवर्क्स के साथ उपयोग किया जाता है, और अन्य।

अलग तरह के एपीआई के लिए विशेष दृष्टिकोण की आवश्यकता होती है।
यहाँ एक साइड-बाय-साइड सपोर्ट तुलना है संरचित आउटपुट (विश्वसनीय JSON प्राप्त करना) लोकप्रिय LLM प्रदाताओं के बीच, साथ ही न्यूनतम Python उदाहरण

Ollama से संरचित आउटपुट प्राप्त करने के कुछ तरीके
बड़े भाषा मॉडल (LLMs) शक्तिशाली हैं, लेकिन उत्पादन में हम आमतौर पर मुक्त-रूप पेराग्राफ नहीं चाहते। बजाय इसके, हम प्रत्याशित डेटा चाहते हैं: विशेषताएं, तथ्य, या संरचित वस्तुएं जिन्हें आप एक ऐप में फीड कर सकते हैं। यह है LLM संरचित आउटपुट।