
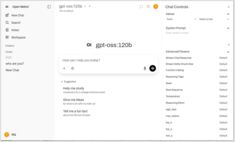
开放 WebUI:自托管 LLM 界面
适用于本地大语言模型的自托管ChatGPT替代方案
Open WebUI 是一个功能强大、可扩展且功能丰富的自托管网页界面,用于与大型语言模型进行交互。
适用于本地大语言模型的自托管ChatGPT替代方案
Open WebUI 是一个功能强大、可扩展且功能丰富的自托管网页界面,用于与大型语言模型进行交互。
通过 OpenAI API 实现快速的 LLM 推理
vLLM 是由加州大学伯克利分校 Sky Computing Lab 开发的用于大型语言模型 (LLMs) 的高性能、内存高效的推理和服务引擎。
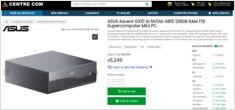
现在从澳大利亚零售商处获得真实的AUD定价
NVIDIA DGX Spark (GB10 Grace Blackwell) 现已在澳大利亚 now available in Australia 主要电脑零售商处有现货销售。 如果你一直在关注 全球 DGX Spark 价格和供货情况, 你可能会对澳大利亚的价格感兴趣,价格范围从 6,249 至 7,999 澳元,具体取决于存储配置和零售商。

人工智能生成内容检测技术指南
AI生成内容的泛滥带来了一个新的挑战:区分真正的原创人类写作与“AI劣质内容”(AI劣质内容)——低质量、批量生产的合成文本。

使用本地LLM测试Cognee - 实际效果
Cognee 是一个 Python 框架,用于使用 LLM 从文档中构建知识图谱。 但它能与自托管模型一起使用吗?

使用 BAML 和 Instructor 实现类型安全的 LLM 输出
在生产环境中使用大型语言模型时,获取结构化、类型安全的输出至关重要。
两个流行的框架——BAML 和 Instructor——采用不同的方法来解决这个问题。

关于自托管Cognee中使用LLM的思考
选择 最适合 Cognee 的 LLM 需要平衡图构建质量、幻觉率和硬件限制。
Cognee 在使用较大且低幻觉模型(32B+)时表现优异,例如通过 Ollama,但中等规模的模型也适用于较轻量的设置。
必备快捷键和神奇命令
使用基本的快捷键、魔法命令和工作流程技巧,快速提升你的数据科学和开发体验,从而启动 Jupyter Notebook 生产力。

使用 Python 和 Ollama 构建 AI 搜索代理
Ollama 的 Python 库现在包含原生的 OLlama 网络搜索 功能。只需几行代码,你就可以使用网络上的实时信息增强本地 LLM,从而减少幻觉并提高准确性。

为你的RAG堆栈选择合适的向量数据库
选择合适的向量数据库可以决定你的RAG应用的性能、成本和可扩展性。这篇全面的比较涵盖了2024-2025年最受欢迎的选项。

使用 Go 和 Ollama 构建 AI 搜索代理
Ollama 的 Web 搜索 API 可以让您将本地 LLM 与实时网络信息相结合。本指南将向您展示如何在 Go 中实现 网络搜索功能,从简单的 API 调用到功能齐全的搜索代理。

掌握本地LLM部署,对比12+工具
本地部署大型语言模型 随着开发人员和组织寻求增强的隐私性、减少延迟和对AI基础设施的更大控制权,变得越来越流行。

使用 Go 微服务构建强大的 AI/ML 管道
随着人工智能和机器学习工作负载变得越来越复杂,对强大的编排系统的需求也变得更为迫切。Go语言的简洁性、性能和并发特性使其成为构建机器学习流水线的编排层的理想选择,即使模型本身是用Python编写的。

在共享的嵌入空间中统一文本、图像和音频
跨模态嵌入 代表了人工智能领域的一项突破,它使不同数据类型能够在统一的表示空间中实现理解和推理。

在预算硬件上部署企业级AI,使用开放模型
人工智能的民主化已经到来。
借助像 Llama 3、Mixtral 和 Qwen 这样的开源大语言模型(LLM),团队现在可以使用消费级硬件构建强大的 AI 基础设施 - 在降低成本的同时,仍能完全控制数据隐私和部署。

LongRAG、Self-RAG、GraphRAG - 下一代技术
检索增强生成(RAG) 已经远远超越了简单的向量相似性搜索。 LongRAG、Self-RAG 和 GraphRAG 代表了这些能力的前沿。