

在 Python 中运行 FLUX.1-dev GGUF Q8
使用GGUF量化加速FLUX.1-dev
FLUX.1-dev 是一款功能强大的文本到图像模型,能够生成令人惊叹的结果,但其24GB以上的内存需求使得在许多系统上运行变得具有挑战性。 FLUX.1-dev的GGUF量化版本 提供了一种解决方案,将内存使用量减少约50%,同时保持出色的图像质量。
使用GGUF量化加速FLUX.1-dev
FLUX.1-dev 是一款功能强大的文本到图像模型,能够生成令人惊叹的结果,但其24GB以上的内存需求使得在许多系统上运行变得具有挑战性。 FLUX.1-dev的GGUF量化版本 提供了一种解决方案,将内存使用量减少约50%,同时保持出色的图像质量。

在 Docker Model Runner 中配置上下文大小的变通方法
在 Docker Model Runner 中配置上下文大小 比它应该的要复杂得多。

用于根据文本指令增强图像的AI模型
Black Forest Labs 已发布 FLUX.1-Kontext-dev,这是一款先进的图像到图像 AI 模型,它可以通过文本指令增强现有图像。

启用 NVIDIA CUDA 支持的 Docker 模型运行器的 GPU 加速功能
Docker Model Runner 是 Docker 官方用于本地运行 AI 模型的工具,但
在 Docker Model Runner 中启用 NVidia GPU 加速
需要特定的配置。

对比无头 CMS - 功能、性能与使用场景
选择合适的无头CMS可以决定你的内容管理策略是成功还是失败。
让我们比较三种影响开发人员构建内容驱动型应用的开源解决方案。

通过自托管的 Nextcloud 云存储掌控您的数据
nextcloud 是领先的开源、自托管云存储和协作平台,让您完全掌控自己的数据。

您在自托管人工智能驱动备份中的照片
Immich 是一款革命性的开源、自托管照片和视频管理解决方案,它赋予你对记忆的完全控制权。凭借与 Google Photos 相媲美的功能,包括人工智能驱动的人脸识别、智能搜索和自动手机备份,同时确保你的数据在你自己的服务器上保持私密和安全。

用于搜索、索引和分析的 Elasticsearch 命令
Elasticsearch 是一个基于 Apache Lucene 构建的强大分布式搜索和分析引擎。 这份全面的速查表涵盖了使用 Elasticsearch 集群时的基本命令、最佳实践和快速参考。

GPT-OSS 120b 在三个 AI 平台上的基准测试
我找到了一些关于GPT-OSS 120b在三个不同平台上运行的性能测试结果:NVIDIA DGX Spark、Mac Studio和RTX 4080。Ollama库中的GPT-OSS 120b模型大小为65GB,这意味着它无法装入RTX 4080(或更新的RTX 5080的16GB显存中。
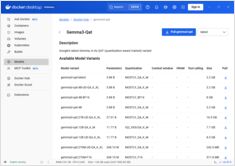
Docker Model Runner 命令快速参考
Docker Model Runner (DMR) 是 Docker 官方用于本地运行 AI 模型的解决方案,于 2025 年 4 月推出。此快速参考提供了所有关键命令、配置和最佳实践的快速查阅。
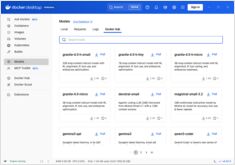
对比 Docker Model Runner 和 Ollama 本地大语言模型
在本地运行大型语言模型 (LLMs) 已成为隐私保护、成本控制和离线功能的重要趋势。 2025 年 4 月,Docker 推出了 Docker Model Runner (DMR),这是其用于 AI 模型部署的官方解决方案,标志着该领域的重大转变。
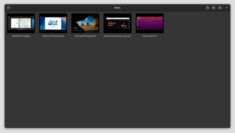
使用 GNOME Boxes 管理 Linux 虚拟机
在当今的计算环境中,虚拟化已成为开发、测试和运行多个操作系统的重要工具。对于寻求一种简单直观方式来管理虚拟机的 Linux 用户来说,GNOME Boxes 是一个轻量且用户友好的选择,它在不牺牲功能性的前提下优先考虑易用性。
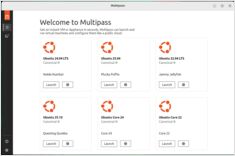
多阶段安装、设置和基本命令
Multipass 是一个轻量级的虚拟机管理工具,使您能够轻松地在 Linux、Windows 和 macOS 上创建和管理 Ubuntu 云实例。

探索超越谷歌和必应的替代搜索引擎
虽然谷歌在全球搜索引擎市场中占据着超过90%的市场份额,但一个日益增长的替代搜索引擎生态系统正在提供不同的网络搜索方法。

专用芯片正在让人工智能推理变得更加快速、廉价。

掌控您的内容,管理您的身份