
Open WebUI: Antarmuka LLM yang Dapat Dijalankan Sendiri
Alternatif Self-hosted ChatGPT untuk LLM Lokal
Open WebUI adalah antarmuka web self-hosted yang kuat, dapat diperluas, dan fitur lengkap untuk berinteraksi dengan model bahasa besar.
Alternatif Self-hosted ChatGPT untuk LLM Lokal
Open WebUI adalah antarmuka web self-hosted yang kuat, dapat diperluas, dan fitur lengkap untuk berinteraksi dengan model bahasa besar.
Inferensi LLM yang Cepat dengan API OpenAI
vLLM adalah mesin inferensi dan pelayanan (serving) berbasis throughput tinggi dan efisien penggunaan memori untuk Large Language Models (LLMs) yang dikembangkan oleh Sky Computing Lab dari UC Berkeley.
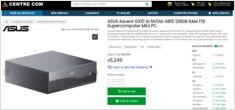
Harga AUD asli dari retailer Australia kini tersedia
The
NVIDIA DGX Spark
(GB10 Grace Blackwell) sekarang
tersedia di Australia
di toko PC utama dengan stok lokal.
Jika Anda telah mengikuti
penawaran harga dan ketersediaan DGX Spark secara global,
Anda mungkin tertarik mengetahui bahwa harga di Australia berkisar antara $6,249 hingga $7,999 AUD tergantung konfigurasi penyimpanan dan toko.

Menguji Cognee dengan LLM lokal - hasil nyata
Cognee adalah kerangka kerja Python untuk membangun grafik pengetahuan dari dokumen menggunakan LLM. Tapi apakah itu bekerja dengan model yang dihosting sendiri?

Pikiran tentang LLM untuk Cognee yang dihosting sendiri
Memilih LLM Terbaik untuk Cognee memerlukan keseimbangan antara kualitas pembuatan graf, tingkat halusinasi, dan pembatasan perangkat keras. Cognee unggul dengan model besar berhalusinasi rendah (32B+) melalui Ollama tetapi pilihan ukuran sedang juga cocok untuk konfigurasi yang lebih ringan.

Bangun agen pencarian AI dengan Python dan Ollama
Perpustakaan Python Ollama sekarang mencakup kemampuan pencarian web OLlama web search. Dengan hanya beberapa baris kode, Anda dapat memperkuat LLM lokal Anda dengan informasi real-time dari web, mengurangi halusinasi dan meningkatkan akurasi.

Pilih vector DB yang tepat untuk tumpukan RAG Anda
Memilih penyimpanan vektor yang tepat dapat menentukan keberhasilan, biaya, dan skalabilitas aplikasi RAG Anda. Perbandingan menyeluruh ini mencakup opsi paling populer pada 2024-2025.

Bangun agen pencarian AI dengan Go dan Ollama
API Pencarian Web Ollama memungkinkan Anda memperluas LLM lokal dengan informasi web secara real-time. Panduan ini menunjukkan cara mengimplementasikan kemampuan pencarian web dalam Go, dari panggilan API sederhana hingga agen pencarian berfitur lengkap.

Harga RAM melonjak 163-619% karena permintaan AI mengganggu pasokan
Pasaran memori sedang mengalami volatilitas harga yang belum pernah terjadi sebelumnya di akhir 2025, dengan harga RAM melonjak secara dramatis di segala segmen.

Masterkan implementasi LLM lokal dengan 12+ alat yang dibandingkan
Penyimpanan lokal LLM telah semakin populer seiring dengan kebutuhan pengembang dan organisasi akan privasi yang lebih baik, latensi yang lebih rendah, dan kontrol yang lebih besar terhadap infrastruktur AI mereka.

Harga GPU Konsumen yang Cocok untuk AI - RTX 5080 dan RTX 5090
Mari kita bandingkan harga untuk GPU konsumen tingkat atas, yang cocok khususnya untuk LLM dan secara umum untuk AI.
Secara khusus saya melihat RTX-5080 dan RTX-5090 harga.

Buatkan AI perusahaan di perangkat keras berbasis anggaran dengan model terbuka
Demokratisasi AI sudah tiba. Dengan LLM open-source seperti Llama 3, Mixtral, dan Qwen kini bersaing dengan model proprietary, tim dapat membangun infrastruktur AI yang kuat menggunakan perangkat keras konsumen - mengurangi biaya sambil mempertahankan kontrol penuh atas privasi data dan penggunaan.

Buat pemantauan infrastruktur yang kuat dengan Prometheus
Prometheus telah menjadi standar de facto untuk memantau aplikasi dan infrastruktur cloud-native, menawarkan pengumpulan metrik, penelusuran, dan integrasi dengan alat visualisasi.
Menguasai pengaturan Grafana untuk pemantauan & visualisasi
Grafana adalah platform open-source terkemuka untuk pemantauan dan observabilitas, mengubah metrik, log, dan pelacakan menjadi wawasan yang dapat diambil tindakan melalui visualisasi yang menarik.

Buat aplikasi stateful dengan skalasi terurut dan data yang bertahan lama
Kubernetes StatefulSets adalah solusi utama untuk mengelola aplikasi berstatus yang memerlukan identitas stabil, penyimpanan permanen, dan pola penyebaran terurut—penting untuk database, sistem terdistribusi, dan lapisan caching.

Percepat FLUX.1-dev dengan kuantisasi GGUF
FLUX.1-dev adalah model teks-ke-gambar yang kuat yang menghasilkan hasil yang luar biasa, tetapi kebutuhan memori 24GB+ membuatnya menantang untuk dijalankan pada banyak sistem. GGUF quantization dari FLUX.1-dev menyediakan solusi, mengurangi penggunaan memori sekitar 50% sambil mempertahankan kualitas gambar yang sangat baik.