
Comparando a adequação das GPUs da NVIDIA para IA
A IA requer muita energia...
No meio da agitação do mundo moderno, estou aqui comparando as especificações técnicas de diferentes placas adequadas para tarefas de IA (Aprendizado Profundo, Detecção de Objetos e LLMs). Elas são todas incrivelmente caras, no entanto.
Para mais informações sobre como a escolha da GPU afeta o throughput do LLM, os limites de VRAM e os benchmarks entre diferentes runtimes, consulte Performance de LLM: Benchmarks, Gargalos & Otimização. Para um guia de compra mais abrangente de 2026 que inclui opções da AMD e Intel, consulte GPUs para IA em 2026: NVIDIA, AMD, Intel Comparadas.

Esta é uma imagem gerada por IA. Não leve a sério…
Vamos dar uma olhada em outras opções, apenas para explorar
| Placa | VRAM | Largura de Barramento | Largura de Banda de Memória | Núcleos CUDA | Núcleos Tensor | Potência (W) |
|---|---|---|---|---|---|---|
| RTX 4060 Ti 16GB | 16 GB | 128-bit | 288 GB/s | 4.352 | 136 | 165 |
| RTX 4070 Ti 16GB | 16 GB | 256-bit | 672 GB/s | 7.680 | 240 | 285 |
| RTX 4080 16GB | 16 GB | 256-bit | 716,8 GB/s | 9.728 | 304 | 320 |
| RTX 4080 Super 16GB | 16 GB | 256-bit | 736 GB/s | 10.240 | 320 | 320 |
| RTX 4090 24GB | 24 GB | 384-bit | 1.008 GB/s | 16.384 | 512 | 450 |
| RTX 5060 Ti 16GB | 16 GB | 128-bit | 448 GB/s | 4.608 | 144 | 180 |
| RTX 5070 Ti 16GB | 16 GB | 256-bit | 896 GB/s | 8.960 | 280 | 300 |
| RTX 5080 16GB | 16 GB | 256-bit | 896 GB/s | 10.752 | 336 | ~320 |
| RTX 5090 32GB | 32 GB | 512-bit | 1.792 GB/s | 21.760 | 680 | ~450 |
| RTX 2000 Ada | 16 GB | 128-bit | 224 GB/s | 2.816 | 88 | 70 |
| RTX 4000 Ada | 20 GB | 160-bit | 280 GB/s | 6.144 | 192 | 70 |
| RTX 4500 Ada | 24 GB | 192-bit | 432 GB/s | 7.680 | 240 | 210 |
| RTX 5000 Ada | 32 GB | 256-bit | 576 GB/s | 12.800 | 400 | 250 |
| RTX 6000 Ada | 48 GB | 384-bit | 960 GB/s | 18.176 | 568 | 300 |
Velocidade estimada de LLM por GPU (base Qwen 3.6 27B)
A tabela abaixo estima o throughput de geração e de prompts a partir de uma linha de base única medida (RTX 4080 16GB), escalando os resultados usando a contagem de núcleos CUDA e a largura de banda de memória. Isso fornece uma referência prática de planejamento ao comparar placas NVIDIA para inferência local.
| GPU | Núcleos CUDA | Largura de Banda | Gen. Est. (t/s) | Prompt Est. (t/s) | MTP Est. máx 2 Gen | MTP Est. máx 2 Prompt |
|---|---|---|---|---|---|---|
| RTX 4080 16GB | 8.192 | 912 GB/s | 45 (medido) | 200 (medido) | 75 (medido) | 151 (medido) |
| RTX 4090 24GB | 12.000 | 1.008 GB/s | ~50 | ~260 | ~82 | ~220 |
| RTX 5060 Ti 16GB | 4.608 | 448 GB/s | ~22 | ~100 | ~38 | ~76 |
| RTX 5070 12GB | 6.144 | 672 GB/s | ~34 | ~140 | ~58 | ~114 |
| RTX 5070 Ti 16GB | 8.960 | 896 GB/s | ~44 | ~190 | ~74 | ~145 |
| RTX 5080 16GB | 10.752 | 960 GB/s | ~45 | ~250 | ~76 | ~195 |
| RTX 5090 32GB | 21.760 | 1.792 GB/s | ~85 | ~390 | ~140 | ~310 |
| RTX PRO 4000 24GB | 6.144 | 672 GB/s | ~34 | ~140 | ~58 | ~114 |
| RTX PRO 4500 32GB | 7.680 | 896 GB/s | ~44 | ~175 | ~74 | ~138 |
| RTX PRO 5000 48GB | 12.800 | 1.344 GB/s | ~60 | ~300 | ~100 | ~240 |
| RTX PRO 6000 96GB | 21.760 | 1.792 GB/s | ~85 | ~390 | ~140 | ~310 |
Estes números são estimativas aproximadas, não resultados de benchmark para cada placa. A velocidade real depende do tamanho do modelo, quantização, comprimento do contexto e pilha de software. O desempenho pode cair drasticamente se um modelo não couber totalmente na VRAM e começar a usar a memória da CPU.
Para resultados medidos entre plataformas, consulte NVIDIA DGX Spark vs Mac Studio vs RTX-4080. Para escolhas de modelos que cabem na VRAM, consulte Melhor LLM em GPU com 16 GB de VRAM.
Largura de Banda de Memória:
- RTX 5090 (1.792 GB/s), depois RTX 4090 (1.008 GB/s), depois RTX 6000 Ada (960 GB/s)
Núcleos Tensor:
- RTX 5090 (680), depois RTX 6000 Ada (568), depois RTX 4090 (512)
Núcleos CUDA
- RTX 5090 (21.760), depois RTX 6000 Ada (18.176), depois RTX 4090 (16.384)
RAM
- RTX 6000 Ada (48 GB), depois RTX 5090 e RTX 5000 Ada (32 GB), depois RTX 4090 (24 GB)
Preços na Austrália
- RTX 6000 Ada: 12.000 AUD
- RTX 5090: 6.000 AUD
- RTX 5000 Ada: 7.000 AUD
- RTX 4090: esgotado
Melhor GPU de consumo para LLM
Ainda assim, acho que a RTX 5090 seria a melhor escolha para aprendizado de máquina, aprendizado profundo, IA e até LLM :)…
Preços Reais
Um pouco caro…

E os preços reais da RTX 5090 são 50% mais altos do que o esperado. Olhe isso!
Isso é de 15/05/2025
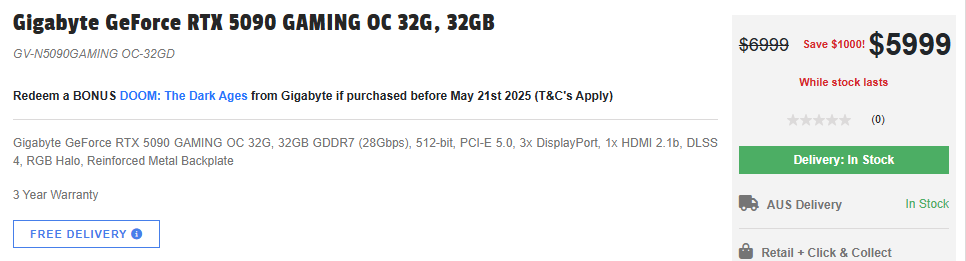
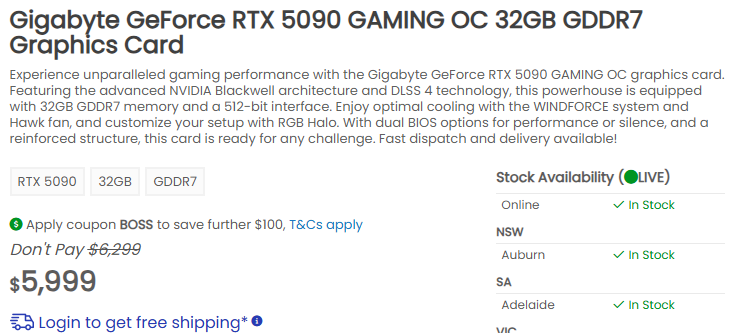
Para explorar benchmarks de LLM, requisitos de VRAM e ajuste de desempenho em diferentes GPUs e runtimes, confira nosso hub de Performance de LLM: Benchmarks, Gargalos & Otimização. Para planejamento de multi-GPU e plataforma, consulte Infraestrutura de IA em Hardware de Consumo e Performance de LLM e Pinos PCIe.
