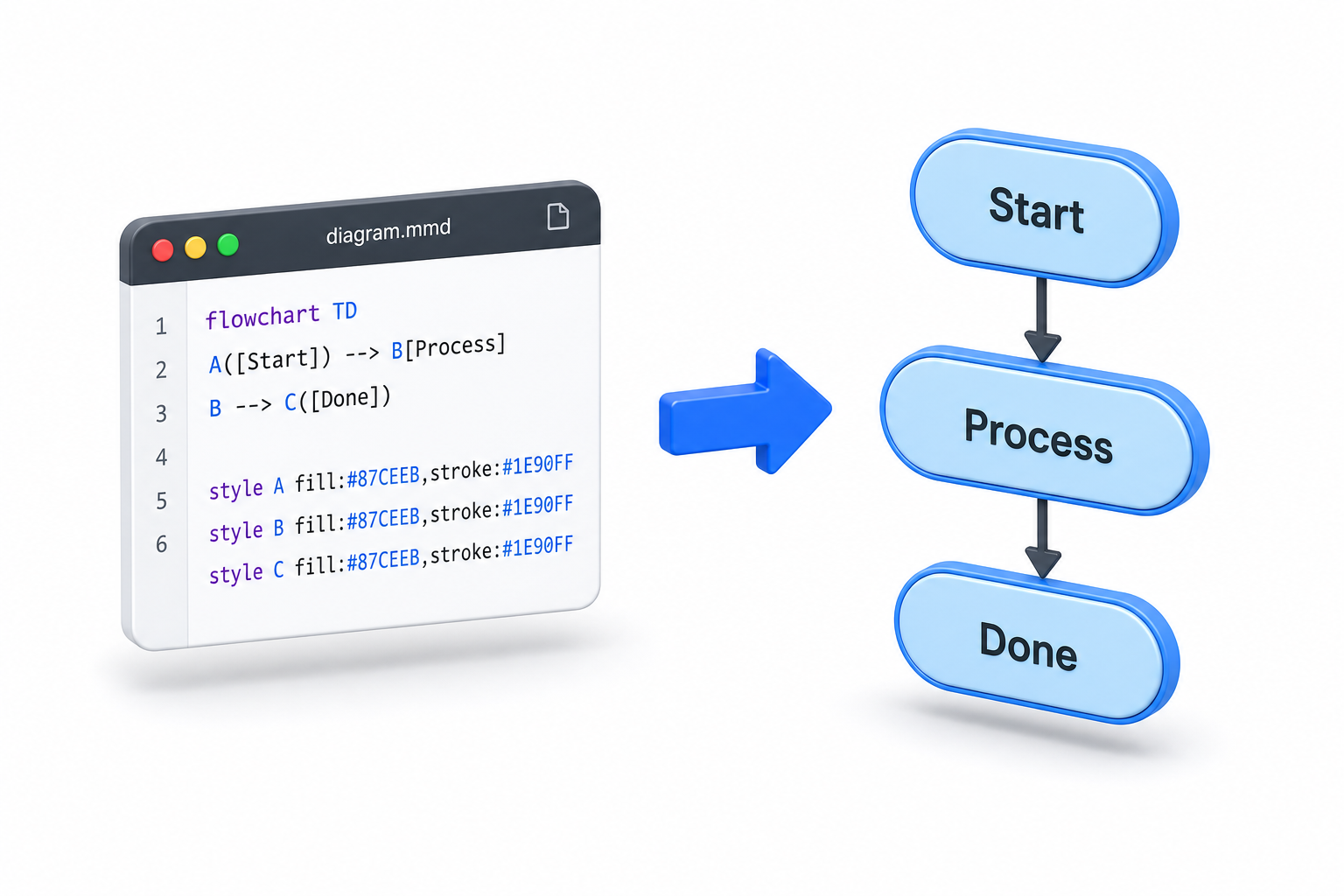
Podman Quadlet vs Docker Compose para serviços Linux
Escolha o fluxo de trabalho de contêineres adequado.
Docker Compose e Podman Quadlet resolvem problemas sobrepostos, mas vêm de centros de design diferentes, e a escolha entre eles depende de você pensar em pilhas de aplicativos ou em serviços Linux.