Aggiungere il supporto per GPU NVIDIA a Docker Model Runner
Abilita l'accelerazione GPU per Docker Model Runner con supporto NVIDIA CUDA
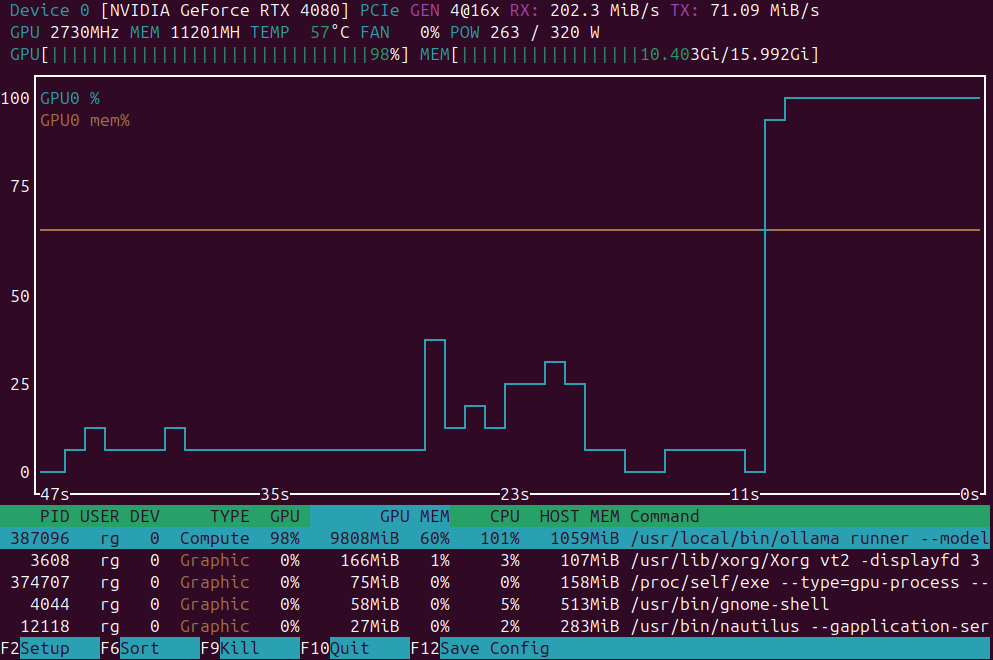
Docker Model Runner è lo strumento ufficiale di Docker per eseguire modelli AI in locale, ma abilitare l’accelerazione GPU di NVidia in Docker Model Runner richiede una configurazione specifica.