
NVIDIA DGX Spark vs Mac Studio vs RTX-4080: Ollama 성능 비교
GPT-OSS 120b의 세 AI 플랫폼에서의 벤치마크
저는 Ollama에서 실행되는 GPT-OSS 120b의 성능 테스트 결과를 NVIDIA DGX Spark, Mac Studio, RTX 4080 세 가지 플랫폼에서 확인해보았습니다. Ollama 라이브러리에서 제공하는 GPT-OSS 120b 모델의 크기는 65GB로, RTX 4080의 16GB VRAM에 맞지 않으며, 더 최근의 RTX 5080에도 맞지 않습니다.
예, CPU로 부분적으로 오프로딩하여 실행할 수 있으며, 64GB의 시스템 RAM이 있다면(저는 그런 환경을 가지고 있습니다) 시도해볼 수 있습니다. 하지만 이 설정은 생산성에 근접하지는 않습니다. 정말로 고부하 작업이 필요한 경우, NVIDIA DGX Spark와 같은 장비가 필요할 수 있습니다. 이 장비는 고용량 AI 작업에 특화되어 있습니다.
LLM 성능에 대한 더 많은 정보는 처리량 대 지연 시간, VRAM 제한, 런타임 및 하드웨어에 걸친 벤치마크에 대해 LLM 성능: 벤치마크, 병목 현상 및 최적화에서 확인할 수 있습니다.

DGX Spark 같은 “고-RAM AI 장비"에서 이 LLM이 크게 이점을 얻을 것으로 기대했습니다. 결과는 좋지만, DGX Spark와 더 저렴한 옵션 사이의 가격 차이를 고려할 때 예상보다 그렇게 크게 차이가 나지 않았습니다.
TL;DR
Ollama에서 실행되는 GPT-OSS 120b의 세 가지 플랫폼에서의 성능 비교:
| 장비 | 프롬프트 평가 성능 (토큰/초) | 생성 성능 (토큰/초) | 비고 |
|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | 가장 우수한 성능, 완전히 GPU 가속 |
| Mac Studio | 미상 | 34 → 6 | 하나의 테스트에서 컨텍스트 크기가 증가할수록 성능이 저하됨 |
| RTX 4080 | 969 | 12.45 | VRAM 제한으로 인해 CPU 78% / GPU 22% 분할 |
모델 사양:
- 모델: GPT-OSS 120b
- 파라미터: 117B (Mixture-of-Experts 아키텍처)
- 패스당 활성 파라미터: 5.1B
- 양자화: MXFP4
- 모델 크기: 65GB
이 아키텍처는 Qwen3:30b와 같은 다른 MoE 모델과 유사하지만, 훨씬 더 큰 규모로 설계되었습니다.
NVIDIA DGX Spark에서의 GPT-OSS 120b
NVIDIA DGX Spark의 LLM 성능 데이터는 공식 Ollama 블로그 게시물에서 나옵니다 (다음의 유용한 링크 섹션에 포함되어 있습니다). DGX Spark는 NVIDIA가 개인용 AI 슈퍼컴퓨터 시장에 진입한 제품으로, 대규모 언어 모델을 실행하기 위해 특별히 설계된 128GB의 통합 메모리가 포함되어 있습니다.

GPT-OSS 120b의 생성 성능은 41 토큰/초로 매우 인상적이며, 이는 이 특정 모델에서 가장 우수한 성능을 보여줍니다. 이는 매우 큰 모델에 대해 추가 메모리 용량이 실제로 차이를 만든다는 것을 보여줍니다.
그러나 중간 규모의 LLM 성능은 그렇게 인상적이지 않습니다. 특히 Qwen3:32b와 Llama3.1:70b와 같은 모델에서 이 현상이 두드러지며, 고 RAM 용량이 예상되는 모델에서 이러한 성능은 가격 차이에 비해 인상적이지 않습니다. 30-70B 파라미터 범위의 모델을 주로 사용하는 경우, 정확히 구성된 워크스테이션과 같은 대안을 고려하거나, 48GB VRAM을 갖춘 Quadro RTX 5880 Ada를 고려하는 것이 좋습니다.
Mac Studio Max에서의 GPT-OSS 120b
Youtube 채널 Slinging Bits는 다양한 컨텍스트 크기에서 Ollama를 사용하여 GPT-OSS 120b를 실행하는 포괄적인 테스트를 수행했습니다. 결과는 심각한 성능 문제를 보여줍니다: 컨텍스트 크기가 증가함에 따라 생성 속도가 34 토큰/초에서 단지 6 토큰/초로 급격히 감소했습니다.
이 성능 저하는 메모리 압력과 macOS가 통합 메모리 아키텍처를 관리하는 방식으로 인해 발생할 가능성이 큽니다. Mac Studio Max는 M2 Ultra 구성에서 최대 192GB의 통합 메모리가 특징이지만, 매우 큰 모델을 처리하는 방식은 전용 GPU VRAM과는 크게 다릅니다.


변화하는 컨텍스트 길이에 걸쳐 일관된 성능이 필요한 경우, GPT-OSS 120b에 대해 Mac Studio는 그 외의 탁월한 AI 작업 성능에도 불구하고 적합하지 않습니다. 더 작은 모델을 사용하거나 Ollama의 병렬 요청 처리 기능을 사용하여 생산 환경에서 처리량을 극대화하는 것이 더 나을 수 있습니다.
RTX 4080에서의 GPT-OSS 120b
처음에는 소비자용 PC에서 Ollama와 GPT-OSS 120b를 실행하는 것이 특별히 흥미롭지 않을 것이라고 생각했지만, 결과는 제게 기쁨을 안겨주었습니다. 이 쿼리로 테스트했을 때 다음과 같은 일이 발생했습니다:
$ ollama run gpt-oss:120b --verbose Compare the weather in state capitals of Australia
Thinking...
We need to compare weather in state capitals of Australia. Provide a comparison, perhaps include
...
*All data accessed September 2024; any updates from the BOM after that date may slightly adjust the
numbers, but the broad patterns remain unchanged.*
total duration: 4m39.942105769s
load duration: 75.843974ms
prompt eval count: 75 token(s)
prompt eval duration: 77.341981ms
prompt eval rate: 969.72 tokens/s
eval count: 3483 token(s)
eval duration: 4m39.788119563s
eval rate: 12.45 tokens/s
이제 흥미로운 부분입니다—이 LLM과 함께 Ollama는 대부분 CPU에서 실행되고 있습니다! 모델은 16GB VRAM에 맞지 않기 때문에 Ollama는 대부분을 시스템 RAM으로 스마트하게 오프로딩합니다. ollama ps 명령을 사용하여 이 행동을 확인할 수 있습니다:
$ ollama ps
NAME ID SIZE PROCESSOR CONTEXT
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
78% CPU / 22% GPU 분할로 실행되더라도 RTX 4080은 이 크기의 모델에 대해 꽤 우수한 성능을 제공합니다. 프롬프트 평가는 969 토큰/초로 매우 빠르고, 12.45 토큰/초의 생성 속도는 많은 애플리케이션에서 사용 가능합니다.
이것은 다음과 같은 점을 고려할 때 특히 인상적이며:
- 모델은 사용 가능한 VRAM의 거의 4배 크기입니다
- 대부분의 계산은 CPU에서 이루어집니다 (이로 인해 제 64GB의 시스템 RAM이 이점이 됩니다)
- Ollama가 CPU 코어를 사용하는 방식을 이해하면 이 설정을 더 최적화할 수 있습니다
소비자용 GPU가 117B 파라미터 모델을 처리할 수 있다는 것을 누가 예상했겠습니까, 그것도 사용 가능한 성능으로 말이죠? 이는 Ollama의 스마트한 메모리 관리 능력과 충분한 시스템 RAM의 중요성을 보여줍니다. Ollama를 애플리케이션에 통합하려는 경우, Python과 Ollama 사용에 대한 이 가이드를 확인해보세요.
참고: 이는 실험 및 테스트에는 적합하지만, GPT-OSS가 몇 가지 특이한 점을 가질 수 있음을 주의 깊게 살펴보는 것이 필요합니다, 특히 구조화된 출력 형식에서.
더 많은 벤치마크, VRAM 및 CPU 오프로딩의 트레이드오프, 그리고 플랫폼 간 성능 최적화에 대한 정보는 LLM 성능: 벤치마크, 병목 현상 및 최적화 허브에서 확인할 수 있습니다.
주요 출처
- Ollama on NVIDIA DGX Spark: Performance Benchmarks - 공식 Ollama 블로그 게시물, DGX Spark 성능 데이터 포함
- GPT-OSS 120B on Mac Studio - Slinging Bits YouTube - 다양한 컨텍스트 크기에서 GPT-OSS 120b 테스트에 대한 자세한 동영상
하드웨어 비교 및 Ollama 관련 읽기
- DGX Spark vs. Mac Studio: NVIDIA의 개인용 AI 슈퍼컴퓨터에 대한 실용적, 가격 비교 - DGX Spark 구성, 전 세계 가격, 로컬 AI 작업에 대한 Mac Studio와의 직접 비교
- NVIDIA DGX Spark - 기대 - DGX Spark 초기 보도: 가용성, 가격, 기술 사양
- NVidia RTX 5080 및 RTX 5090 호주 가격 - 2025년 10월 - 차세대 소비자용 GPU의 현재 시장 가격
- Quadro RTX 5880 Ada 48GB은 AI 작업에 적합한가요? - AI 작업에 대한 48GB 워크스테이션 GPU 대안 리뷰
- Ollama cheatsheet - Ollama에 대한 포괄적인 명령 참조 및 팁
P.S. 새로운 데이터
이 글을 게시한 후에 NVIDIA 사이트에서 DGX Spark에서의 LLM 추론에 대한 추가 통계를 발견했습니다:
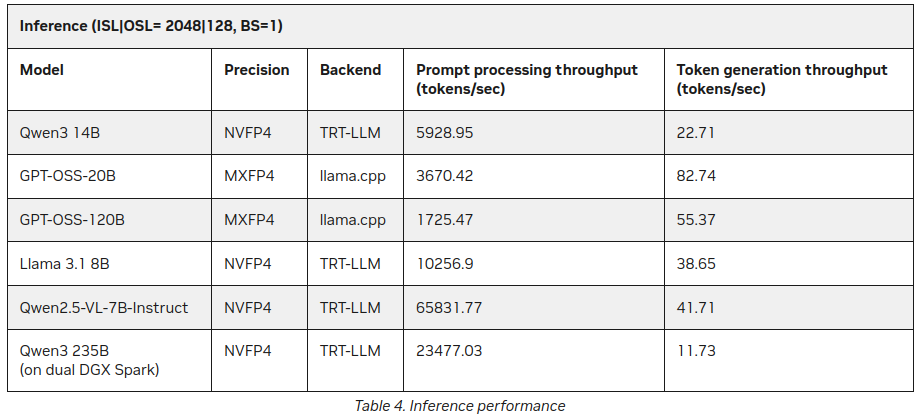
더 나은 데이터이지만, 위에서 언급한 내용과 크게 충돌하지는 않습니다 (55 토큰 대 41) 하지만 Qwen3 235B (이중 DGX Spark에서)가 초당 11개 이상의 토큰을 생성하는 점은 흥미로운 추가 정보입니다.
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks/
