

리눅스 서비스를 위한 Podman Quadlet과 Docker Compose 비교
적절한 컨테이너 워크플로우를 선택하세요.
Docker Compose와 Podman Quadlet은 겹치는 문제를 해결하지만 서로 다른 설계 관점에서 출발했으며, 이 중 무엇을 선택할지는 애플리케이션 스택으로 사고하는지 아니면 리눅스 서비스로 사고하는지에 따라 달라집니다.
적절한 컨테이너 워크플로우를 선택하세요.
Docker Compose와 Podman Quadlet은 겹치는 문제를 해결하지만 서로 다른 설계 관점에서 출발했으며, 이 중 무엇을 선택할지는 애플리케이션 스택으로 사고하는지 아니면 리눅스 서비스로 사고하는지에 따라 달라집니다.

원격 데스크톱 액세스를 지원하는 Headless Hermes 서버
데스크톱 클라이언트에서 다른 머신의 헤드리스 서버에 Hermes 에이전트를 실행하고 연결하려면 두 개의 서버 프로세스와 하나의 클라이언트 연결이 필요합니다.
systemd에서 부팅 시 Docker Compose를 관리합니다.
리눅스 서버에서 Docker Compose는 부팅 시 시작되고, 종료 시 깨끗하게 멈춰야 하며, 수동 개입 없이 재부팅을 견뎌야 합니다.

Ubuntu에서 적절한 Docker 설치 경로를 선택하세요.
Ubuntu에 Docker를 설치하는 것은 간단해 보이지만, 실제로는 동일한 명령어 이름을 놓고 경쟁하는 여러 Docker 관련 옵션들이 존재합니다. 각 옵션은 패키징, 업그레이드 동작, 보안 영향 측면에서 차이가 있습니다.

AI 에이전트를 위한 신뢰할 수 있는 폴링 패턴
폴링 에이전트(Polling Agent)는 AI 어시스턴트 아키텍처에서 가장 화려하지는 않지만, 동시에 가장 유용한 구성 요소 중 하나입니다.
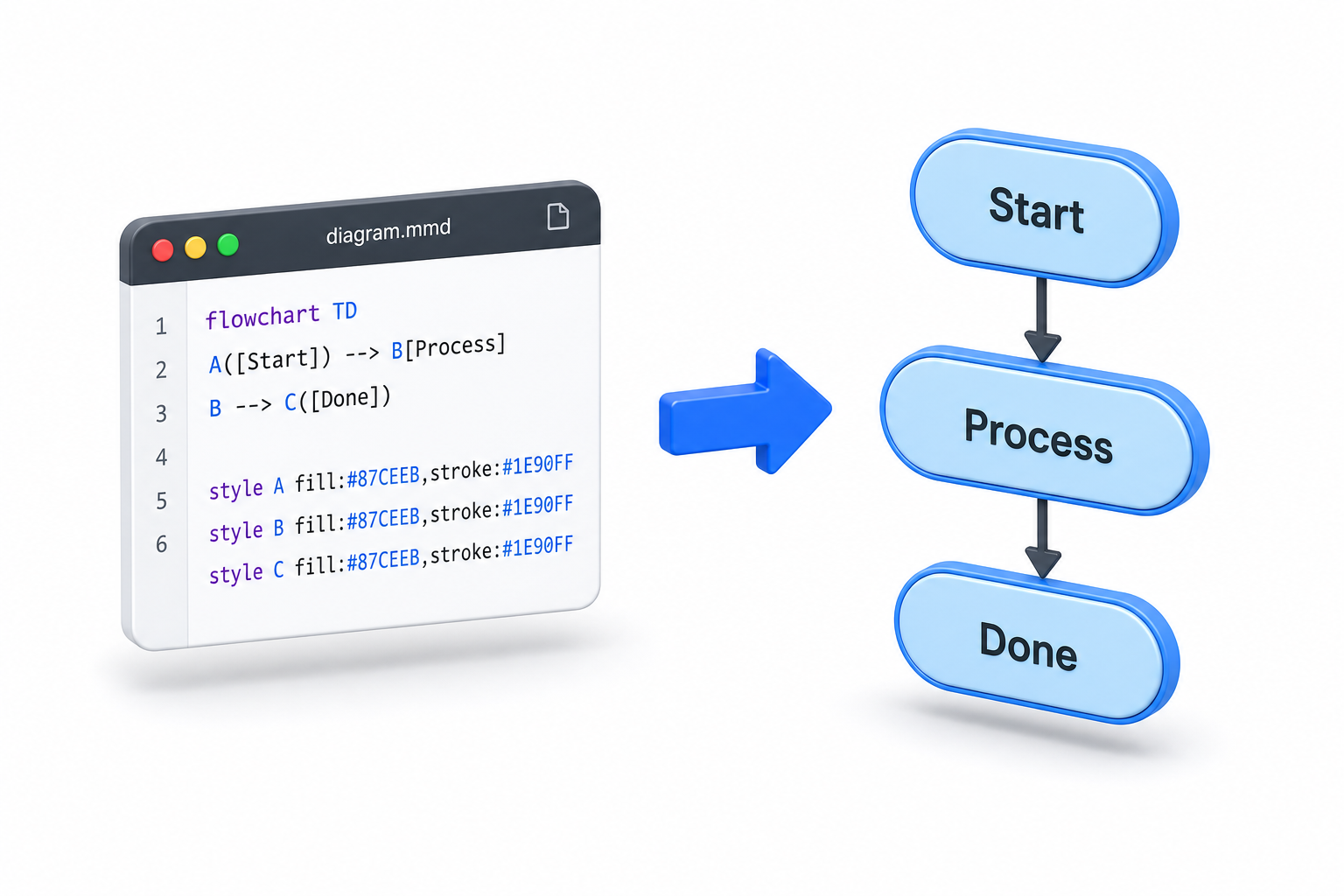
드라마 없이, 코드 기반 다이어그램
Mermaid는 캔버스에서 상자를 드래그하는 대신 다이어그램을 텍스트로 작성하려는 사람들을 위한 텍스트 기반 다이어그램 도구입니다. 이 도구는 마크다운과 유사한 구문을 사용하여 플로우차트, 시퀀스 다이어그램, 클래스 다이어그램, 상태 머신, 타임라인, 간트 차트, 엔티티 관계 다이어그램 등을 설명합니다.

실제 심각한 수준의 어시스턴트는 어떻게 구축되는가
생산 환경용 AI 어시스턴트는 단순히 “프롬프트가 붙은 LLM"이 아닙니다. 이는 의도(Intent)를 받아들이고, 상태를 유지하며, 언제 검색하거나 행동할지 결정하고, 실패를 디버깅할 수 있는 충분한 런타임 세부 정보를 제공하는 시스템입니다.

llama-server를 종료하지 않고도 VRAM을 확보하는 방법
llama.cpp 라우터 모드는 수년 동안 llama-server에 도입된 변화 중 가장 유용한 변화 중 하나입니다. 이는 로컬 LLM 운영자에게 Ollama에서 기대하는 모델 관리 경험에 가까운 기능을 제공하면서도, llama.cpp를 처음부터 사용하게 만드는 원시 성능과 저레벨 제어를 그대로 유지합니다.

자체 호스팅 LLM에서 Hermes 카んばん 부하를 제어하세요.
Hermes Agent는 칸반 스타일의 보드와 Hermes Gateway를 함께 제공하며, 너무 많은 작업이 한 번에 배포되면 자체 호스팅 LLM을 포화 상태로 만들 수 있습니다.

리스타트 없이 LLM을 배포하고 교체하세요.
오랜 기간 동안 llama.cpp에는 뚜렷한 한계가 존재했습니다.
즉, 프로세스당 단 하나의 모델만 서빙(serving)할 수 있었으며, 모델을 변경하려면 재시작이 필요했습니다.

플러그인이 우선입니다. 스킬 명칭은 간략하게 표기합니다.
이 기사는 OpenClaw 플러그인에 대해 다룹니다. OpenClaw 플러그인은 채널, 모델 제공자, 도구, 음성, 메모리, 미디어, 웹 검색 및 기타 런타임 표면을 추가하는 네이티브 게이트웨이 패키지입니다.

개발자를 위한 Hermes Agent 설치 및 빠른 시작
Hermes Agent은 로컬 머신이나 저비용 VPS에서 실행되는 자체 호스팅(self-hosted) 모델 독립형(model-agnostic) AI 어시스턴트입니다. 터미널 및 메시징 인터페이스를 통해 작동하며, 반복적인 작업을 재사용 가능한 스킬(skills)로 전환하여 시간이 지남에 따라 성능을 향상시킵니다.

공용 포트를 사용하지 않는 원격 Ollama 접근
Ollama 는 로컬 데몬 (daemon) 으로 취급될 때 가장 행복해합니다: CLI 와 애플리케이션이 루프백 HTTP API 와 통신하며, 나머지 네트워크는 Ollama 의 존재를 전혀 알지 못합니다.

GPU 와 영속성을 갖춘 Compose 우선 Ollama 서버
Ollama 는 베어 메탈 (bare metal) 환경에서 훌륭하게 작동합니다. 이를 서비스처럼 다룰 때 더욱 흥미로운데, 안정적인 엔드포인트, 고정된 버전, 영구 저장소, 그리고 GPU 가 있거나 없는 명확한 상태를 보장받기 때문입니다.

스트리밍 응답을 깨뜨리지 않고 HTTPS를 사용한 Ollama
리버스 프록시 뒤에 Ollama 를 실행하는 것은 HTTPS, 선택적 접근 제어, 예측 가능한 스트리밍 동작을 얻는 가장 간단한 방법입니다.

상태 유지 스트리밍, 체크포인트, K8s, PyFlink, Go.
Apache Flink 는 유계 및 무계 데이터 스트림에 대한 상태 기반 연산을 위한 프레임워크입니다.