

LLM Wiki 관리: 드리프트, 모순 및 검토
컴파일된 지식의 신뢰성을 유지하세요
LLM 위키(Wiki)는 오래된 사실이 여전히 그럴듯해 보일 때, 모순이 정교하게 다듬어질 때, 그리고 생성된 요약이 원천 자료에서 벗어나면 실패합니다.
컴파일된 지식의 신뢰성을 유지하세요
LLM 위키(Wiki)는 오래된 사실이 여전히 그럴듯해 보일 때, 모순이 정교하게 다듬어질 때, 그리고 생성된 요약이 원천 자료에서 벗어나면 실패합니다.

3개 벤더 간 AI GPU 비교
2026년 AI 하드웨어 시장은 크게 변화했습니다. NVIDIA, AMD, 인텔은 모두 로컬 대규모 언어 모델(LLM)과 AI 추론 워크로드를 처리할 수 있는 GPU를 필요로 하는 개발자들을 두고 치열한 경쟁을 벌이고 있습니다.

원격 데스크톱 액세스를 지원하는 Headless Hermes 서버
데스크톱 클라이언트에서 다른 머신의 헤드리스 서버에 Hermes 에이전트를 실행하고 연결하려면 두 개의 서버 프로세스와 하나의 클라이언트 연결이 필요합니다.
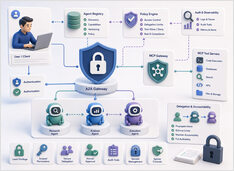
프로토콜 보안은 모델이 아닌 행위 주체를 규정합니다.
프롬프트 인젝션은 LLM 시스템에서 가장 많은 보안 관심을 받고 있으며, 주목받을 만하지만 에이전트가 도구를 호출하고 작업을 다른 에이전트에 위임하기 시작하면 이것이 유일한 문제는 아닙니다.
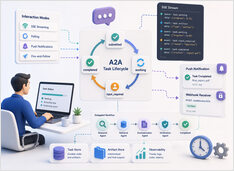
장기간 실행되는 A2A 작업은 채팅 세션보다 더 오래 지속됩니다.
대부분의 AI 에이전트 데모는 여전히 몇 가지 추가 단계를 거친 채팅 완성(chat completion)과 비슷하게 작동합니다. 프롬프트를 보내고 몇 초를 기다린 후, 하나의 응답으로 답변을 받습니다.

품질 저하 없이 LLM 추론 속도를 높이는 방법 - 실무 가이드
70B 모델은 한 번의 순전파(forward pass)에서 하나의 토큰을 생성하며, 각 패스마다 VRAM에서 가중치를 다시 로드하고 컨텍스트 전반에 걸쳐 어텐션을 계산하며 메모리를 동기화합니다. 토큰 사이에는 GPU가 순차적 의존성이 해결될 때까지 대기하며 유휴 상태에 머무릅니다.

A2A는 사라진 것이 아닙니다. 다만 범용적으로 쓰이지 않을 뿐입니다.
구글의 에이전트 투 에이전트(Agent2Agent) 프로토콜, 즉 A2A는 첫해를 다소 혼란스럽게 보냈습니다.

AI 에이전트를 위한 신뢰할 수 있는 폴링 패턴
폴링 에이전트(Polling Agent)는 AI 어시스턴트 아키텍처에서 가장 화려하지는 않지만, 동시에 가장 유용한 구성 요소 중 하나입니다.

MCP는 에이전트에 도구를 제공합니다. A2A는 에이전트에 동료(peer)를 제공합니다.
AI 에이전트 아키텍처가 두 개의 레이어로 나뉘기 시작하고 있습니다.

A2A는 에이전트를 네트워크 피어(network peers)로 전환합니다.
A2A 프로토콜(에이전트 투 에이전트 프로토콜)은 독립적인 AI 에이전트 시스템 간의 통신을 위한 개방형 표준입니다.
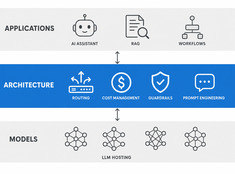
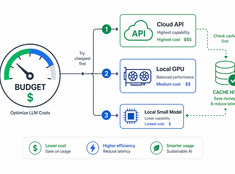
중요한 곳에 토큰을 투자하세요.
LLM(대형 언어 모델) 비용은 사용량에 따라 선형적으로 증가합니다. 하루에 1,000개의 요청을 처리하고 요청당 비용이 $0.01인 시스템의 경우, 일일 비용은 $100이며 연간 비용은 $365입니다. 기업 규모에서는 이 비용이 $10,000을 넘을 수 있습니다.
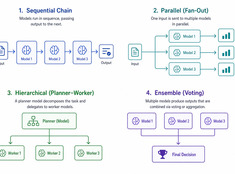
작동하는 가장 단순한 패턴을 선택하라.
단일 모델 시스템은 단순합니다. 다중 모델 시스템은 강력합니다. 여기서 핵심 과제는 모델을 선택하는 것이 아니라, 이러한 모델들을 조율하는 아키텍처를 설계하는 것입니다.
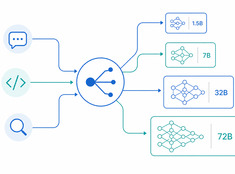
적절한 작업에 적합한 모델
200단어짜리 이메일을 요약하기 위해 700억 파라미터 모델 실행은 낭비입니다. 프로덕션 코드를 검토하기 위해 30억 파라미터 모델을 실행하는 것은 무모합니다. 대부분의 시스템은 이 두 극단 사이의 어딘가에 위치해 있으며, 바로 여기서 모델 라우팅(Model Routing)의 역할이 시작됩니다.
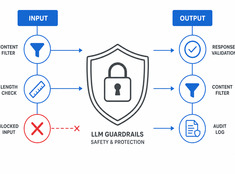
모델이 아닌 리스크를 통제하십시오.
대형 언어 모델(LLM)은 예측 불가능합니다. 환각(hallucination) 현상이 발생하거나, 데이터가 유출되거나, 유해한 콘텐츠를 생성하거나, 합법적인 요청을 거부하기도 합니다. 가드레일(Guardrails)은 모델의 성능을 희생하지 않으면서도 모델의 행동을 제한합니다.

에이전트의 작업 기억, 구조화 기억 및 검색 기억
메모리는 어시스턴트를 반응형에서 지속형으로 전환시키지만, 동시에 많은 시스템이 조용히 부패하는 곳이기도 합니다. 설문 조사들은 단기적 대 장기적 이분법이 현대 에이전트 메모리에는 더 이상 충분하지 않다고 주장하며, OpenAI와 LangGraph SDK들은 작동 메모리(working memory), 내구 상태(durable state), 검색(retrieval)이라는 더 단순한 스택을 지향합니다.