
NVIDIA DGX Spark vs Mac Studio vs RTX-4080: Ollama-prestatielijst
GPT-OSS 120b benchmarks op drie AI-platforms
Ik vond enkele interessante prestatietests van GPT-OSS 120b die draaien op Ollama over drie verschillende platforms: NVIDIA DGX Spark, Mac Studio, en RTX 4080. De GPT-OSS 120b model uit de Ollama bibliotheek weegt 65 GB, wat betekent dat het niet past in de 16 GB VRAM van een RTX 4080 (of de nieuwere RTX 5080).
Ja, het model kan draaien met gedeeltelijke uitlating naar de CPU, en als je 64 GB systeemgeheugen hebt (zoals ik), kun je het proberen. Echter, deze opstelling zou niet als iets dat dicht bij productie-klare prestaties zou worden beschouwd. Voor werkladingen die echt veel vereisen, zou je iets nodig hebben zoals de NVIDIA DGX Spark, die specifiek is ontworpen voor hoge-capaciteit AI werkladingen. Voor meer over LLM prestaties—doorstroming versus vertraging, VRAM limieten en benchmarks over runtime en hardware—zie LLM prestaties: benchmarks, bottlenecks & optimalisatie.

Ik verwachtte dat deze LLM aanzienlijk zou profiteren van het draaien op een “hoog-RAM AI apparaat” zoals de DGX Spark. Hoewel de resultaten goed zijn, zijn ze niet zo dramatisch beter als je zou verwachten gegeven de prijsverschillen tussen DGX Spark en betaalbare opties.
TL;DR
Ollama draaiend met GPT-OSS 120b prestatievergelijking over drie platforms:
| Apparaat | Prompt Eval Prestaties (tokens/sec) | Generatieprestaties (tokens/sec) | Opmerkingen |
|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | Beste overal prestaties, volledig GPU-geaccelereerd |
| Mac Studio | Onbekend | 34 → 6 | Een test toonde afname met toename van contextgrootte |
| RTX 4080 | 969 | 12.45 | 78% CPU / 22% GPU split vanwege VRAM limieten |
Model specificaties:
- Model: GPT-OSS 120b
- Parameters: 117B (Mixture-of-Experts architectuur)
- Actieve parameters per pass: 5.1B
- Quantisatie: MXFP4
- Modelgrootte: 65GB
Dit is vergelijkbaar in architectuur met andere MoE modellen zoals Qwen3:30b, maar op een veel grotere schaal.
GPT-OSS 120b op NVIDIA DGX Spark
De LLM prestatiedata voor NVIDIA DGX Spark komt van de officiële Ollama blogpost (vermeld hieronder in de nuttige linkssectie). De DGX Spark vertegenwoordigt NVIDIA’s entree in de persoonlijke AI supercomputer markt, met 128 GB geïntegreerd geheugen dat specifiek is ontworpen voor het draaien van grote taalmodellen.

De prestaties van GPT-OSS 120b zien er indrukwekkend uit met 41 tokens/sec voor generatie. Dit maakt het duidelijk winnaar voor dit specifieke model, wat aantoont dat de extra geheugencapaciteit echt een verschil kan maken voor zeer grote modellen.
De prestaties van gemiddelde tot grote LLMs zien er echter niet zo overtuigend uit. Dit is vooral merkbaar met Qwen3:32b en Llama3.1:70b—precies de modellen waarbij je zou verwachten dat de hoge RAM capaciteit zou schitteren. De prestaties op DGX Spark voor deze modellen zijn niet inspirerend in vergelijking met de prijsvoordeel. Als je vooral werkt met modellen in de 30-70B parameter bereik, zou je misschien overwegen alternatieven zoals een goed ingevoerde werkstation) of zelfs een Quadro RTX 5880 Ada met zijn 48 GB VRAM.
GPT-OSS 120b op Mac Studio Max
De Slinging Bits YouTube-kanaal heeft uitgebreide tests uitgevoerd met GPT-OSS 120b draaiend op Ollama met verschillende contextgroottes. De resultaten tonen een aanzienlijk prestatieprobleem: de generatiesnelheid van het model daalde dramatisch van 34 tokens/s naar slechts 6 tokens/s met toenemende contextgrootte.
Deze prestatievermindering is waarschijnlijk te wijten aan geheugendruk en de manier waarop macOS de geïntegreerde geheugenarchitectuur beheert. Hoewel Mac Studio Max indrukwekkende geïntegreerde geheugen heeft (tot 192 GB in de M2 Ultra configuratie), is de manier waarop het grote modellen beheert onder toenemende contextbelastingen aanzienlijk anders dan bij toegewijde GPU VRAM.


Voor toepassingen die consistente prestaties vereisen over verschillende contextlengtes, maakt dit Mac Studio minder ideaal voor GPT-OSS 120b, ondanks zijn overige uitstekende mogelijkheden voor AI werkladingen. Je zou betere kans hebben met kleinere modellen of overwegen om Ollama’s parallele aanvraagbehandeling kenmerken te gebruiken om doorstroming te maximaliseren in productiescenario’s.
GPT-OSS 120b op RTX 4080
Ik dacht aanvankelijk dat het draaien van Ollama met GPT-OSS 120b op mijn consumentenpc niet erg opvallend zou zijn, maar de resultaten hebben me aangenaam verrast. Hier is wat er gebeurde toen ik het testte met deze query:
$ ollama run gpt-oss:120b --verbose Vergelijk het weer in de hoofdsteden van Australië
Denkend...
We moeten het weer in de hoofdsteden van Australië vergelijken. Geef een vergelijking, misschien inclusief
...
*Alle data toegankelijk September 2024; eventuele updates van de BOM na die datum kunnen de getallen licht aanpassen, maar de brede patronen blijven onveranderd.*
totaal duur: 4m39.942105769s
laadduur: 75.843974ms
prompt eval tellen: 75 token(s)
prompt eval duur: 77.341981ms
prompt eval snelheid: 969.72 tokens/s
eval tellen: 3483 token(s)
eval duur: 4m39.788119563s
eval snelheid: 12.45 tokens/s
Nu is hier het interessante deel—Ollama met deze LLM draait vooral op CPU! Het model past gewoon niet in de 16 GB VRAM, dus Ollama verlaadt intelligent de meeste van het model naar systeemgeheugen. Je kunt dit gedrag bekijken met de ollama ps commando:
$ ollama ps
NAAM ID GROOTTE VERWERKER CONTEXT
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
Hoewel het draait met een 78% CPU / 22% GPU split, levert de RTX 4080 toch respectabele prestaties voor een model van deze grootte. De prompt evaluatie is ongelooflijk snel met 969 tokens/s, en zelfs de generatiesnelheid van 12.45 tokens/s is bruikbaar voor veel toepassingen.
Dit is vooral indrukwekkend als je bedenkt dat:
- Het model bijna 4x groter is dan de beschikbare VRAM
- De meeste berekeningen plaatsvinden op CPU (wat voordelen heeft van mijn 64 GB systeemgeheugen)
- Het begrijpen van hoe Ollama CPU-kernen gebruikt kan helpen bij verdere optimalisatie van deze opstelling
Wie had gedacht dat een consumenten GPU een 117B parameter model zou kunnen aanpakken, laat staan met bruikbare prestaties? Dit toont de kracht van Ollama’s intelligente geheugenbeheer en de belangrijkheid van voldoende systeemgeheugen te hebben. Als je geïnteresseerd bent in het integreren van Ollama in jouw toepassingen, bekijk dan deze gids over het gebruiken van Ollama met Python.
Opmerking: Hoewel dit werkt voor experimenten en testen, zul je GPT-OSS kan enkele quirks hebben, vooral met gestructureerde uitvoerformaten.
Om meer benchmarks, VRAM en CPU offloading trade-offs, en prestatieoptimalisatie over platforms te verkennen, bekijk dan onze LLM prestaties: benchmarks, bottlenecks & optimalisatie hub.
Primair bronmateriaal
- Ollama op NVIDIA DGX Spark: prestatiebenchmarks - Officiële Ollama blogpost met uitgebreide DGX Spark prestatiedata
- GPT-OSS 120B op Mac Studio - Slinging Bits YouTube - Gedetailleerde video test van GPT-OSS 120b met variabele contextgroottes
Gerelateerde lezing over hardware vergelijking en Ollama
- DGX Spark versus Mac Studio: een praktisch, prijsgecontroleerd overzicht van NVIDIA’s persoonlijke AI supercomputer - Gedetailleerde uitleg van DGX Spark configuraties, wereldwijde prijzen en directe vergelijking met Mac Studio voor lokale AI werk
- NVIDIA DGX Spark - Verwachtingen - Eerste dekking van DGX Spark: beschikbaarheid, prijzen en technische specificaties
- NVidia RTX 5080 en RTX 5090 prijzen in Australië - oktober 2025 - Huidige marktprijzen van de volgende generatie consumenten GPUs
- Is de Quadro RTX 5880 Ada 48GB goed? - Beoordeling van de 48GB werkstation GPU alternatief voor AI werkladingen
- Ollama cheatsheet - Uitgebreide commandoreferentie en tips voor Ollama
P.S. Nieuwe gegevens
Al na het publiceren van deze post vond ik op de NVIDIA site extra statistieken over LLM inferentie op DGX Spark:
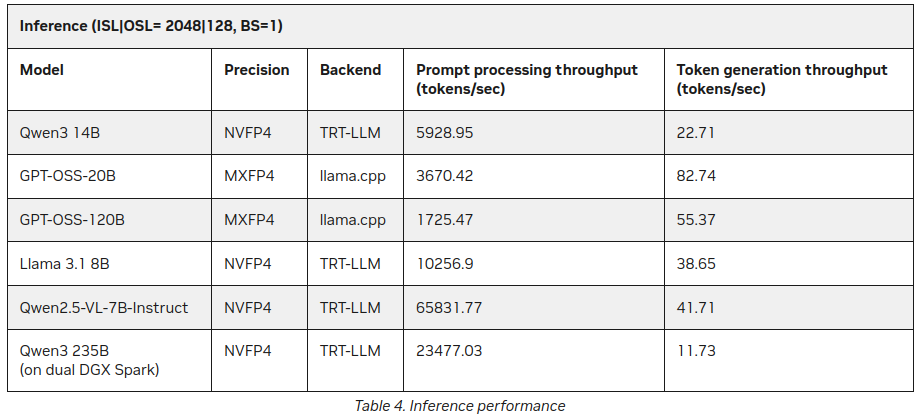
Beter, maar niet veel in tegenspraak met het bovenstaande (55 tokens versus 41), maar het is een interessante aanvulling, vooral over Qwen3 235B (op dubbele DGX Spark) die 11+ tokens per seconde produceert
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks
