

LLM Wiki-onderhoud: Drift, tegenstrijdigheden en evaluatie
Houd samengestelde kennis betrouwbaar
Een LLM Wiki faalt wanneer oude feiten aannemelijk blijven, tegenstrijdigheden worden gepolijst en gegenereerde samenvattingen afwijken van hun bronnen.
Houd samengestelde kennis betrouwbaar
Een LLM Wiki faalt wanneer oude feiten aannemelijk blijven, tegenstrijdigheden worden gepolijst en gegenereerde samenvattingen afwijken van hun bronnen.

Vergelijking van AI-GPU’s van drie leveranciers
Het landschap van AI-hardware is in 2026 aanzienlijk verschoven, waarbij NVIDIA, AMD en Intel allemaal concurreren om ontwikkelaars die GPUs nodig hebben die geschikt zijn voor het lokaal draaien van grote taalmodellen (LLMs) en AI-inferentiewerklasten.
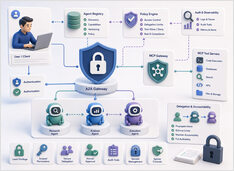
Protocolbeveiliging bepaalt wie mag handelen, niet het model.
Promptinjectie krijgt de meeste aandacht op het gebied van beveiliging in LLM-systemen, en dat is terecht, maar het is niet het enige probleem zodra agents tools gaan aanroepen en werk delegeren aan andere agents.
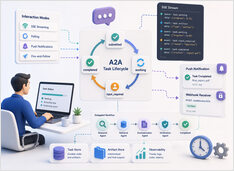
Langlopende A2A-taaken overleven chatsessies.
De meeste AI-agentdemonstraties gedragen zich nog steeds als chat-completies met extra stappen: je stuurt een prompt, wacht enkele seconden en ontvangt een antwoord in één reactie.

Snellere LLM-inferentie zonder kwaliteitsverlies – een praktische handleiding
Een model van 70B (70 miljard parameters) genereert één token per forward pass, en bij elke pass worden de gewichten opnieuw van het VRAM geladen, wordt de attention berekend over de context en wordt het gehege synchroniseerd. Tussen tokens zit de GPU inactief terwijl hij wacht tot sequentiële afhankelijkheden zijn opgelost.

De specificatie als bron van waarheid, niet als bijlage.
Spec-gedreven ontwikkeling is één van die ideeën waarnaar software-ingenieurs eerder hebben gegrepen en vervolgens hebben opzijgezet toen de inspanning niet meer opwog.

Specificaties als enige waarheid, of traad ceremonieel?
Spec-gedreven ontwikkeling kwam in 2026 binnen als het serieuze antwoord van ontwikkelaars op de afwijking van ‘vibe coding’.

A2A is niet dood. Het is gewoon niet universeel.
Het Agent2Agent-protocol van Google, vaak afgekort tot A2A, had een vreemd eerste jaar.

Betrouwbare pollingpatronen voor AI-agents.
Pollende agents behoren tot de minst glamourrijze onderdelen van de architectuur van AI-assistents, maar ze zijn ook een van de meest nuttige.

MCP biedt agents tools. A2A biedt agents collega’s.
De architectuur van AI-agents begint zich op te splitsen in twee lagen.

A2A maakt van agents netwerkpeers.
Het A2A-protocol, kort voor Agent2Agent Protocol, is een open standaard voor communicatie tussen onafhankelijke AI-agentensystemen.
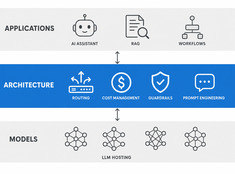
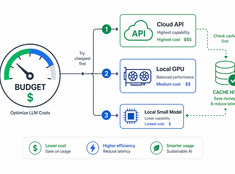
Besteed tokens waar het echt toe doet.
De kosten van LLM’s schalen lineair met het gebruik. Een systeem dat 10.000 verzoeken per dag verwerkt tegen $0,01 per verzoek kost dagelijks $100 — jaarlijks $365. Op enterprise-schaal is dat meer dan $10.000.
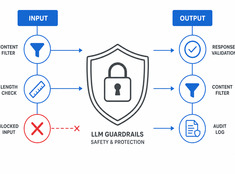
Beheers het risico, niet alleen het model.
LLM’s zijn onvoorspelbaar. Ze hallucineren, lekken data, genereren schadelijke inhoud of weigeren legitieme verzoeken. Guardrails (beveiligingsmaatregelen) beperken het modelgedrag zonder de capaciteiten ten koste te gaan.
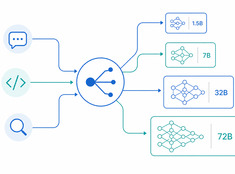
Het juiste model voor de juiste taak.
Het draaien van een model met 70 miljard parameters om een e-mail van 200 woorden samen te vatten, is zonde van de middelen. Het gebruiken van een model van 3 miljard parameters om productiecode te reviewen, is roekeloos. De meeste systemen zitten ergens daar tussenin — en daar komt modelrouting om de hoek kijken.
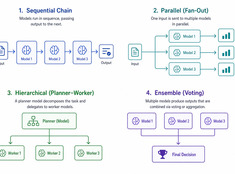
Kies het eenvoudigste patroon dat werkt.
Single-modelsystemen zijn eenvoudig. Multi-modelsystemen zijn krachtig. De uitdaging ligt niet in het kiezen van modellen, maar in het ontwerpen van de architectuur die ze orchestreert.