Monitorowanie inferencji LLM w środowisku produkcyjnym (2026): Prometheus i Grafana dla vLLM, TGI oraz llama.cpp
Monitoruj LLM za pomocą Prometheus i Grafana
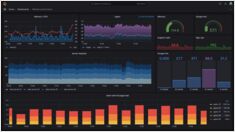
Inferencja LLM wygląda jak „kolejny API" – dopóki nie pojawią się skoki opóźnień, kolejki nie zaczną się zalegać, a Twoje karty GPU nie będą zużywać 95% pamięci bez wyraźnego wyjaśnienia.