

Problemi di Output Strutturato di Ollama GPT-OSS
Non molto bello.
Ollama’s GPT-OSS models presentano frequenti problemi nel gestire l’output strutturato, specialmente quando vengono utilizzate con framework come LangChain, OpenAI SDK, vllm e altri.
Non molto bello.
Ollama’s GPT-OSS models presentano frequenti problemi nel gestire l’output strutturato, specialmente quando vengono utilizzate con framework come LangChain, OpenAI SDK, vllm e altri.

Un paio di modi per ottenere un output strutturato da Ollama
Modelli di grandi dimensioni (LLMs) sono potenti, ma in produzione raramente desideriamo paragrafi liberi. Invece, vogliamo dati prevedibili: attributi, fatti o oggetti strutturati che possiamo alimentare in un’app. Questo è LLM Structured Output.

Ho provato sia Kubuntu che KDE Neon, Kubuntu è più stabile.
Per gli appassionati di KDE Plasma, due distribuzioni Linux vengono spesso menzionate nei dibattiti: Kubuntu e KDE Neon. Potrebbero sembrare simili – entrambe includono KDE Plasma come ambiente desktop predefinito, entrambe si basano su Ubuntu e sono amichevoli per i nuovi utenti.

Il mio test della pianificazione del modello ollama
Ecco che confronto quanta VRAM la nuova versione di Ollama alloca per il modello rispetto alla versione precedente di Ollama. La nuova versione è peggio.

Note sulla configurazione di un indirizzo IP statico in Linux
Questo tutorial ti guiderà attraverso il processo di cambiare l’indirizzo IP statico su un server Ubuntu.

La mia opinione sull'attuale stato dello sviluppo di Ollama
Ollama ha rapidamente diventato uno degli strumenti più popolari per eseguire i modelli LLM localmente. La sua semplice CLI e la gestione semplificata dei modelli l’hanno resa un’opzione di riferimento per gli sviluppatori che desiderano lavorare con i modelli AI al di fuori del cloud.

Piattaforma alternativa di comunicazione VoIP
Mumble è un’applicazione gratuita e open source per la comunicazione vocale tramite IP (VoIP), progettata principalmente per la comunicazione vocale in tempo reale. Utilizza un’architettura client-server in cui gli utenti si connettono a un server condiviso per parlare tra loro.

Panoramica rapida delle interfacce utente più prominenti per Ollama nel 2025
Locally hosted Ollama consente di eseguire modelli linguistici di grandi dimensioni sul proprio computer, ma l’utilizzo tramite riga di comando non è particolarmente utente-friendly. Ecco diversi progetti open-source che forniscono interfacce simili a ChatGPT che si connettono a un Ollama locale.
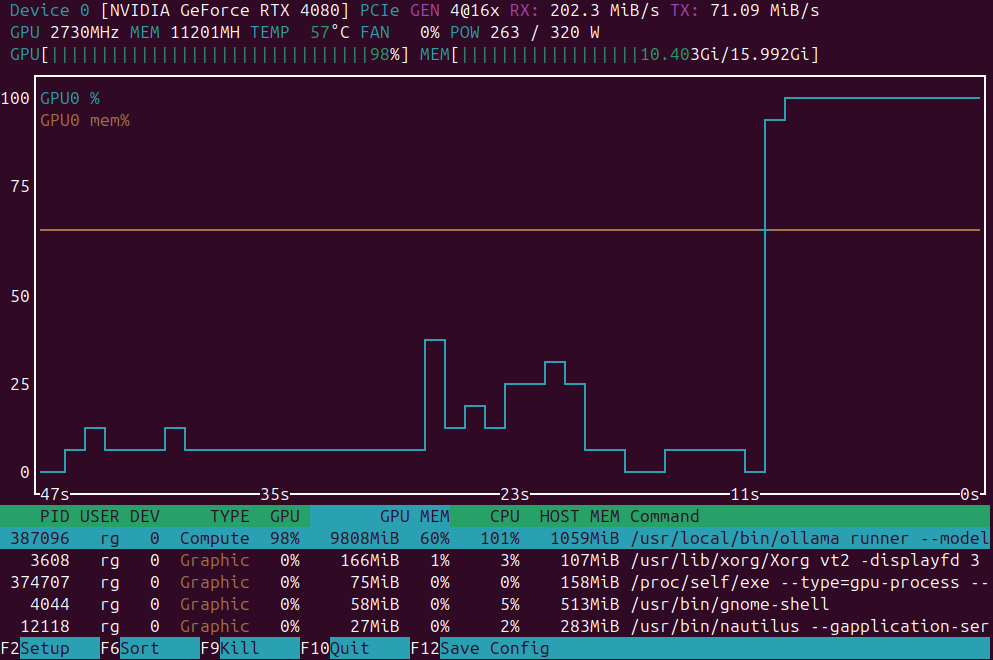
Piccola lista di applicazioni per il monitoraggio del carico della GPU
Applicazioni per il monitoraggio del carico della GPU:
nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.

Installare little k3s Kubernetes su un cluster homelab
Ecco un passo-passo per l’installazione di un cluster K3s a 3 nodi su server bare-metal (1 master + 2 worker).

Breve panoramica delle varianti di Kubernetes
Confrontando le distribuzioni di self-hosting Kubernetes per l’hosting su server a nudo o server domestici, con particolare attenzione alla facilità di installazione, prestazioni, requisiti del sistema e insieme di funzionalità.
Scegliere la migliore versione di Kubernetes per il nostro homelab
Sto confrontando le varianti di Kubernetes auto-hostate adatte all’homelab basato su Ubuntu con 3 nodi (16 GB RAM, 4 core ciascuno), concentrandomi sulla facilità di installazione e manutenzione, il supporto per i volumi persistenti e i LoadBalancer.
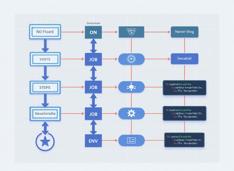
Una breve panoramica su GitHub Actions comuni e la loro struttura.
GitHub Actions è una piattaforma di automazione e CI/CD all’interno di GitHub, utilizzata per costruire, testare e distribuire il tuo codice in base a eventi come push, richieste di pull o su un orario predefinito.

Per inciso, docker-compose è diverso da docker compose...
Ecco un Docker Compose cheat sheet con esempi annotati per aiutarti a padroneggiare rapidamente i file e i comandi di Compose.
Informazioni su Obsidian ...
Ecco un’analisi dettagliata di
Obsidian come potente strumento per la gestione personale della conoscenza (PKM),
che spiega l’architettura, le funzionalità, i punti di forza e il modo in cui supporta i moderni flussi di lavoro per la conoscenza.

Nel luglio 2025, presto dovrebbe essere disponibile
Nvidia sta per rilasciare NVIDIA DGX Spark - un piccolo supercomputer AI basato sull’architettura Blackwell con 128+GB di RAM unificata e un’efficienza AI di 1 PFLOPS. Un dispositivo interessante per eseguire LLM.