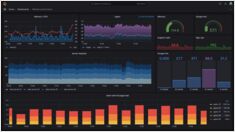
Övervakning av LLM-inferens i produktion (2026): Prometheus & Grafana för vLLM, TGI och llama.cpp
Övervaka LLM med Prometheus och Grafana
LLM-inferens ser ut som “en API till” – fram till dess att latens toppar, köer backar upp och dina GPU:er sitter på 95 % minnesanvändning utan någon uppenbar förklaring.