LLM Wiki-underhåll: Drift, motsägelsefullheter och granskning
Håll sammanställd kunskap pålitlig
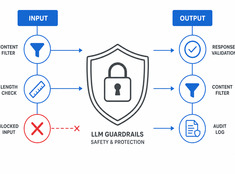
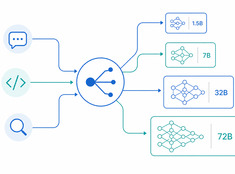
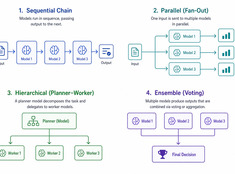
En LLM-wiki misslycks när gamla fakta fortfarande verkar plausibla, motsägelser blir polerade och genererade sammanfattningar drar iväg från sina källor.