
NVIDIA DGX Spark vs. Mac Studio vs. RTX-4080: Ollama-Leistungsvergleich
GPT-OSS 120b Benchmarks auf drei AI-Plattformen
Ich habe einige interessante Leistungsbenchmarks von GPT-OSS 120b gefunden, die auf Ollama unter drei verschiedenen Plattformen durchgeführt wurden: NVIDIA DGX Spark, Mac Studio und RTX 4080. Der GPT-OSS 120b-Modell aus der Ollama-Bibliothek wiegt 65 GB, was bedeutet, dass er nicht in die 16 GB VRAM des RTX 4080 (oder der neueren RTX 5080) passt.
Ja, der Modell kann mit teilweiser Auslagerung auf den CPU laufen, und wenn Sie 64 GB System RAM haben (wie ich), können Sie es ausprobieren. Allerdings wäre diese Konfiguration nicht als produktionstauglich zu betrachten. Für wirklich anspruchsvolle Workloads könnten Sie etwas wie den NVIDIA DGX Spark benötigen, der speziell für hochkapazitive AI-Workloads entwickelt wurde. Für weitere Informationen zur LLM-Leistung – Durchsatz vs. Latenz, VRAM-Grenzen und Benchmarks über Runtime und Hardware – siehe LLM-Leistung: Benchmarks, Engpässe & Optimierung.

Ich erwartete, dass dieser LLM von der Ausführung auf einem „High-RAM AI-Gerät“ wie dem DGX Spark deutlich profitiert. Obwohl die Ergebnisse gut sind, sind sie nicht so dramatisch besser, wie man es vielleicht bei dem Preisunterschied zwischen DGX Spark und günstigeren Optionen erwarten würde.
TL;DR
Ollama mit GPT-OSS 120b Leistungsvergleich über drei Plattformen:
| Gerät | Prompt-Bewertungsleistung (tokens/sec) | Generierungsleistung (tokens/sec) | Hinweise |
|---|---|---|---|
| NVIDIA DGX Spark | 1159 | 41 | Beste Gesamtleistung, vollständig GPU-beschleunigt |
| Mac Studio | Unbekannt | 34 → 6 | Ein Test zeigte eine Verschlechterung bei zunehmender Kontextgröße |
| RTX 4080 | 969 | 12,45 | 78 % CPU / 22 % GPU-Aufteilung aufgrund von VRAM-Grenzen |
Modellspezifikationen:
- Modell: GPT-OSS 120b
- Parameter: 117B (Mischung aus Experten-Architektur)
- Aktive Parameter pro Durchlauf: 5,1B
- Quantisierung: MXFP4
- Modellgröße: 65 GB
Dies ist in der Architektur anderen MoE-Modellen wie Qwen3:30b ähnlich, aber auf einer viel größeren Skala.
GPT-OSS 120b auf NVIDIA DGX Spark
Die LLM-Leistungsdaten für NVIDIA DGX Spark stammen aus dem offiziellen Ollama-Blogbeitrag (siehe unten im Abschnitt „Nützliche Links“). Der DGX Spark repräsentiert den Eintritt von NVIDIA in den Markt für persönliche AI-Supercomputer, mit 128 GB einheitlichem Speicher, der speziell für das Laufen großer Sprachmodelle entwickelt wurde.

Die Leistung von GPT-OSS 120b sieht beeindruckend aus mit 41 tokens/sec bei der Generierung. Dies macht es zum klaren Sieger für dieses Modell, was zeigt, dass die zusätzliche Speicherkapazität für extrem große Modelle wirklich einen Unterschied machen kann.
Die Leistung von mittelgroßen und großen LLMs sieht jedoch nicht so überzeugend aus. Dies ist besonders bei Qwen3:32b und Llama3.1:70b deutlich, genau bei den Modellen, bei denen man erwarten würde, dass die hohe RAM-Kapazität glänzt. Die Leistung auf dem DGX Spark für diese Modelle ist nicht inspirierend im Vergleich zum Preisvorteil. Wenn Sie hauptsächlich mit Modellen im Parameterbereich von 30-70B arbeiten, möchten Sie vielleicht Alternativen wie eine gut konfigurierte Workstation oder sogar einen Quadro RTX 5880 Ada mit seinen 48 GB VRAM in Betracht ziehen.
GPT-OSS 120b auf Mac Studio Max
Der Slinging Bits YouTube-Kanal führte umfassende Tests durch, bei denen GPT-OSS 120b mit Ollama unter unterschiedlichen Kontextgrößen ausgeführt wurde. Die Ergebnisse zeigen ein erhebliches Leistungsproblem: die Generierungsgeschwindigkeit des Modells sank dramatisch von 34 tokens/s auf nur 6 tokens/s, als die Kontextgröße zunahm.
Diese Leistungsverschlechterung ist wahrscheinlich auf Speicherdruck und die Art und Weise zurückzuführen, wie macOS die einheitliche Speicherarchitektur verwaltet. Obwohl der Mac Studio Max beeindruckende einheitliche Speicher (bis zu 192 GB in der M2 Ultra-Konfiguration) hat, unterscheidet sich die Art und Weise, wie er sehr große Modelle unter zunehmenden Kontextlasten verarbeitet, erheblich von dediziertem GPU VRAM.


Für Anwendungen, die eine konsistente Leistung über unterschiedliche Kontextlängen hinweg benötigen, macht dies den Mac Studio weniger ideal für GPT-OSS 120b, trotz seiner sonst hervorragenden Fähigkeiten für AI-Workloads. Sie könnten besser mit kleineren Modellen Erfolg haben oder die Funktionen für parallele Anfragen von Ollama nutzen, um den Durchsatz in Produktionsumgebungen zu maximieren.
GPT-OSS 120b auf RTX 4080
Ich dachte zunächst, dass das Ausführen von Ollama mit GPT-OSS 120b auf meinem Consumer-PC nicht besonders aufregend sein würde, aber die Ergebnisse überraschten mich angenehm. Hier ist, was passierte, als ich es mit dieser Abfrage testete:
$ ollama run gpt-oss:120b --verbose Vergleiche das Wetter in den Hauptstädten Australiens
Denke...
Wir müssen das Wetter in den Hauptstädten Australiens vergleichen. Gib einen Vergleich, vielleicht einbeziehen
...
*Alle Daten abgerufen im September 2024; alle Updates vom BOM nach diesem Datum können die Zahlen leicht anpassen, aber die breiten Muster bleiben unverändert.*
Gesamte Dauer: 4m39.942105769s
Lade Dauer: 75.843974ms
Prompt-Bewertungszähler: 75 Token(s)
Prompt-Bewertungsdauer: 77.341981ms
Prompt-Bewertungsrate: 969.72 Tokens/s
Bewertungszähler: 3483 Token(s)
Bewertungsdauer: 4m39.788119563s
Bewertungsrate: 12.45 Tokens/s
Jetzt kommt der interessante Teil – Ollama mit diesem LLM wurde fast vollständig auf der CPU ausgeführt! Das Modell passt einfach nicht in die 16 GB VRAM, also verlagert Ollama intelligent den Großteil davon in den System-Speicher. Sie können dieses Verhalten mit dem Befehl ollama ps beobachten:
$ ollama ps
NAME ID SIZE PROZESSOR KONTEXT
gpt-oss:120b a951a23b46a1 65 GB 78%/22% CPU/GPU 4096
Trotz der Aufteilung von 78 % CPU / 22 % GPU liefert die RTX 4080 dennoch eine respektable Leistung für ein Modell dieser Größe. Die Prompt-Bewertung ist atemberaubend schnell mit 969 Tokens/s, und sogar die Generierungsgeschwindigkeit von 12,45 Tokens/s ist für viele Anwendungen nutzbar.
Dies ist besonders beeindruckend, wenn man bedenkt, dass:
- Das Modell fast viermal größer ist als die verfügbare VRAM
- Die meisten Berechnungen auf der CPU stattfinden (was von meinen 64 GB System-Speicher profitiert)
- Das Verständnis von wie Ollama CPU-Kerne verwendet kann helfen, diese Konfiguration weiter zu optimieren
Wer hätte gedacht, dass ein Consumer-GPU überhaupt ein Modell mit 117B Parametern verarbeiten könnte, geschweige denn mit nutzbaren Leistungsmerkmalen? Dies zeigt die Kraft von Ollamas intelligenter Speicherverwaltung und die Bedeutung, ausreichend System-Speicher zu haben. Wenn Sie interessiert sind, Ollama in Ihre Anwendungen zu integrieren, schauen Sie sich diese Anleitung an: Ollama mit Python verwenden.
Hinweis: Obwohl dies für Experimente und Tests funktioniert, werden Sie einige Eigenheiten von GPT-OSS feststellen, insbesondere bei strukturierten Ausgabeformaten.
Um weitere Benchmarks, VRAM- und CPU-Auslagerungsgrenzen sowie Leistungsfeinabstimmungen über Plattformen zu erkunden, besuchen Sie unseren LLM-Leistung: Benchmarks, Engpässe & Optimierung Hub.
Primäre Quellen
- Ollama auf NVIDIA DGX Spark: Leistungsbenchmarks - Offizieller Ollama-Blogbeitrag mit umfassenden DGX Spark-Leistungsdaten
- GPT-OSS 120B auf Mac Studio - Slinging Bits YouTube - Detaillierte Video-Testung von GPT-OSS 120b mit unterschiedlichen Kontextgrößen
Verwandte Lektüre zu Hardwarevergleichen und Ollama
- DGX Spark vs. Mac Studio: Ein praktischer, preisgeprüfter Blick auf NVIDIA’s persönlichen AI-Supercomputer - Detaillierte Erklärung der DGX Spark-Konfigurationen, globalen Preise und direkter Vergleich mit Mac Studio für lokale AI-Arbeit
- NVIDIA DGX Spark - Erwartungen - Frühere Berichte zu DGX Spark: Verfügbarkeit, Preise und technische Spezifikationen
- NVidia RTX 5080 und RTX 5090 Preise in Australien - Oktober 2025 - Aktuelle Marktpreise für die nächste Generation Consumer-GPUs
- Ist der Quadro RTX 5880 Ada 48GB gut? - Bewertung der 48 GB Workstation-GPU-Alternative für AI-Workloads
- Ollama cheatsheet - Umfassende Befehlsreferenz und Tipps für Ollama
P.S. Neue Daten
Bereits nachdem ich diesen Beitrag veröffentlicht hatte, fand ich auf der NVIDIA-Website weitere Statistiken zur LLM-Inferein auf DGX Spark:
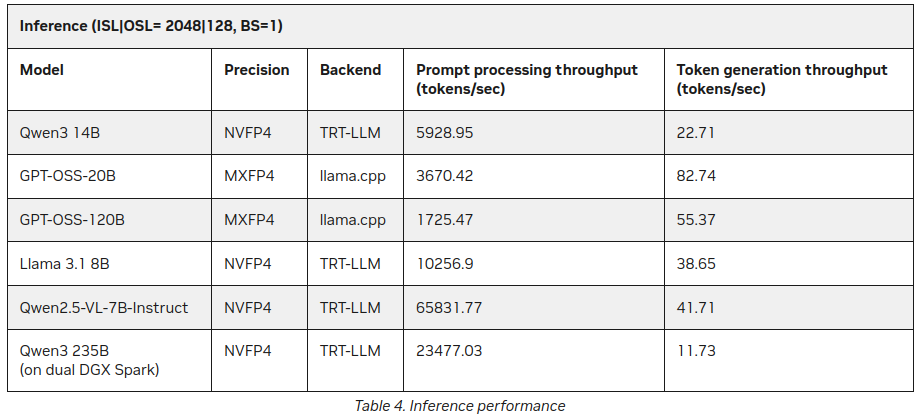
Besser, aber nicht widersprechend zu dem oben gesagten (55 tokens vs 41), aber es ist eine interessante Ergänzung, insbesondere zu Qwen3 235B (auf Doppel-DGX Spark) produziert 11+ tokens/second
https://developer.nvidia.com/blog/how-nvidia-dgx-sparks-performance-enables-intensive-ai-tasks
