Specs, Tests und Code in der KI-Entwicklung synchron halten
Verhindern Sie, dass KI-Agenten von den Spezifikationen, Tests und dem Code abweichen.
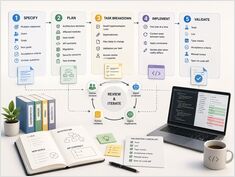
KI-Coding-Agenten liefern Features schnell, aber Spezifikationen, Tests und Code veralten stillschweigend und gehen auseinander. Dieser Leitfaden behandelt ein Nachverfolgungsmodell (Traceability), die Zuordnung von Spezifikation zu Test und von Spezifikation zu Code sowie die CI-Prüfungen, die Abweichungen vor einem Merge erkennen.