Wartung der LLM-Wiki: Drift, Widersprüche und Überprüfung
Sicherstellen, dass kompiliertes Wissen vertrauenswürdig bleibt
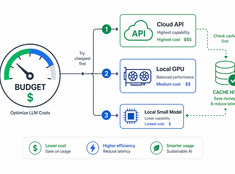
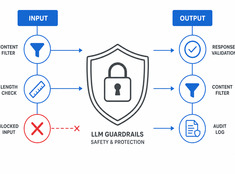
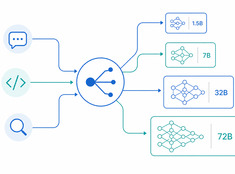
Ein LLM-Wiki scheitert, wenn alte Fakten plausibel bleiben, Widersprüche geglättet werden und generierte Zusammenfassungen von ihren Quellen abweichen.