
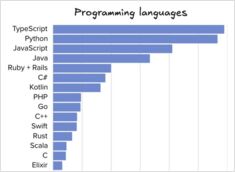
Popularidad de los lenguajes de programación y herramientas para desarrolladores de software
Comparación de herramientas y lenguajes de ingeniería de software
La carta de The Pragmatic Engineer publicada hace unos días presentó estadísticas de una encuesta sobre la popularidad de lenguajes de programación, IDEs, herramientas de IA y otros datos para mediados de 2025.














