Optimisation des coûts pour les systèmes LLM : où va réellement l’argent
Dépensez les jetons là où ils comptent vraiment.
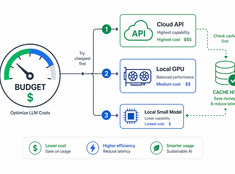
Les coûts des LLM évoluent de manière linéaire avec l’utilisation. Un système traitant 10 000 requêtes par jour à 0,01 $ par requête coûte 100 $ par jour, soit 365 $ par an. À l’échelle de l’entreprise, cela représente plus de 10 000 $.