Мониторинг инференса LLM в продакшене (2026): Prometheus и Grafana для vLLM, TGI и llama.cpp
Мониторинг LLM с помощью Prometheus и Grafana
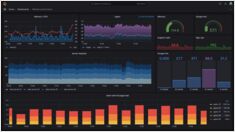
Инференс LLM выглядит как «еще один API» — до тех пор, пока не возникнут скачки задержки, не начнут накапливаться очереди, а ваши GPU не окажутся загружены по памяти на 95% без очевидной причины.