Browser Automatisering in Go: Selenium, chromedp, Playwright, ZenRows
Selenium, chromedp, Playwright, ZenRows - in Go.
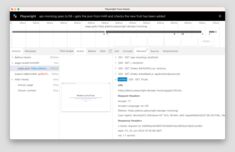
Het kiezen van de juiste browser automatisering stack en webscraping in Go heeft invloed op snelheid, onderhoud en waar je code draait.