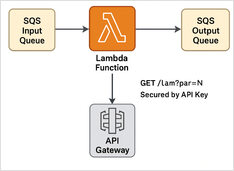
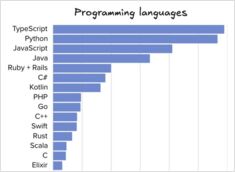
LLM-ASIC's en gespecialiseerde inferentiechips (waarom ze belangrijk zijn)
ASIC's en aangepast silicium verhogen de snelheid en efficiëntie van LLM-inferentie.
De toekomst van AI draait niet alleen om slimmer [modellen](https://www.glukhov.org/nl/rag/embeddings/qwen3-embedding-qwen3-reranker-on-ollama/ “Qwen3 embedding en reranker modellen - state-of-the-art prestaties). Het gaat ook om silicium dat aansluit op de manier waarop deze modellen daadwerkelijk worden aangeboden. Gespecialiseerde hardware voor LLM-inferentie volgt een pad dat doet denken aan de verschuiving in Bitcoin-mining van GPUs naar doelgerichte ASICs, maar met strengere beperkingen omdat modellen en precisie-formules voortdurend evolueren.