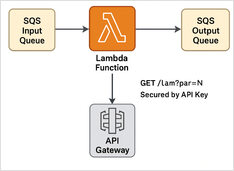
Airtable dla programistów i DevOps - plany, API, Webhooki oraz przykłady w Go i Pythonie
Airtable - ograniczenia planu bezpłatnego, API, webhooks, Go & Python.
Airtable najlepiej można opisać jako platformę o niskim poziomie kodowania, zbudowaną wokół współdzielonego interfejsu “spreadsheet-like” (podobnego do arkusza kalkulacyjnego), który jest świetny do szybkiego tworzenia narzędzi operacyjnych (wewnętrznych śledzi, lekkich CRM, potoków treści, kolejek ocen AI), gdzie nieprogramiści potrzebują przyjaznego interfejsu, a programiści potrzebują powierzchni API do automatyzacji i integracji.