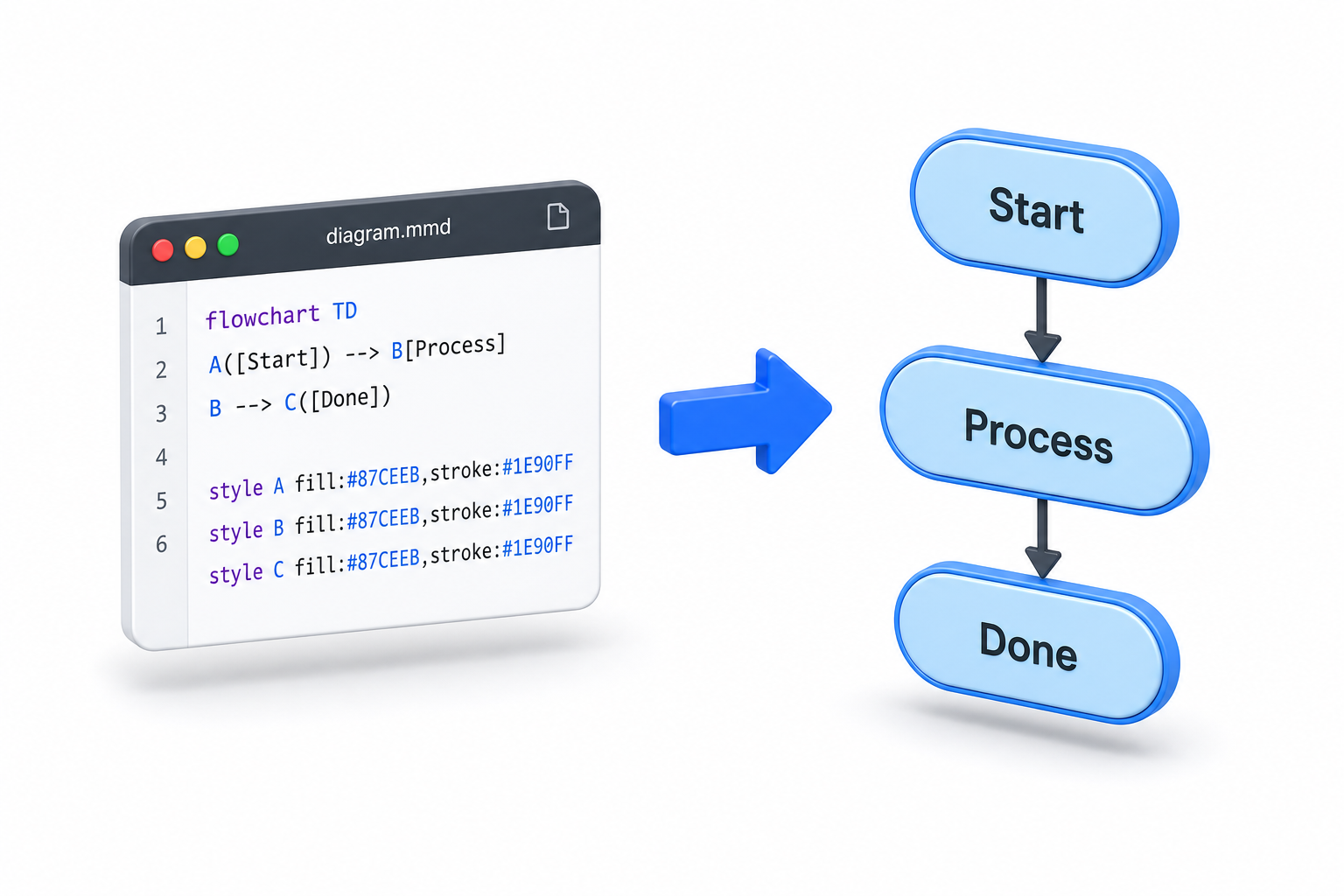
Go context.Context: правильное использование отмены, таймаутов и значений
Контекст в Go — это управление потоком выполнения, а не хранилище.
Использование context.Context в Go достаточно простое, чтобы его можно было легко испортить — и это главная проблема.