Оптимизация затрат для систем LLM: куда на самом деле уходит деньги
Тратьте токены там, где они действительно важны.
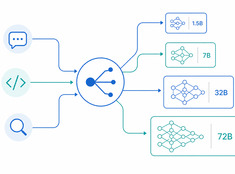
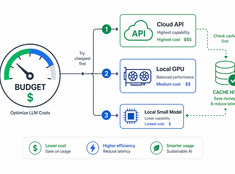
Стоимость использования больших языковых моделей (LLM) растет линейно в зависимости от объема запросов. Система, обрабатывающая 10 000 запросов в день по цене $0,01 за запрос, обходится в $100 ежедневно — это $365 в год. В корпоративном масштабе эта сумма превышает $10 000.