Я постоянно возвращаюсь к llama.cpp для локального вывода — он дает вам контроль, который Ollama и другие абстрагируют, и просто работает. Легко запускать модели GGUF интерактивно с llama-cli или предоставлять совместимый с OpenAI HTTP API с llama-server.
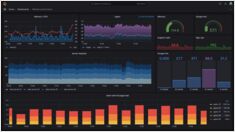
Learn how to monitor LLM inference servers (vLLM, Hugging Face TGI, llama.cpp) using Prometheus and Grafana. This article covers what to measure, how to expose and scrape /metrics, example PromQL queries for p95 latency and tokens/sec, ready-to-use Docker Compose and Kubernetes manifests, Grafana dashboard provisioning, alerting, and real-world troubleshooting.
Стратегия полной наблюдаемости для инференса LLM и приложений LLM
Build an end-to-end observability strategy for LLM inference and LLM applications: what to measure, how to instrument, which tools to use, how to control cardinality and sampling, and how to deploy and scale the telemetry pipeline securely.
Метрики, дашборды и оповещения для производственных систем — Prometheus, Grafana, Kubernetes и рабочие нагрузки ИИ.
Наблюдаемость — это основа надежных производственных систем.
Без метрик, дашбордов и оповещений кластеры Kubernetes дрейфуют, рабочие нагрузки ИИ и LLM молча отказывают, а регрессии задержек остаются незамеченными до тех пор, пока пользователи не пожаловаться.
Настройте надежный мониторинг инфраструктуры с Prometheus
Prometheus
стал де-факто стандартом для мониторинга облачных приложений и инфраструктуры, предлагая сбор метрик, запросы и интеграцию с инструментами визуализации.
Grafana — это ведущая открытая платформа для мониторинга и наблюдения, которая преобразует метрики, логи и трассировки в действенные инсайты через потрясающие визуализации.