

생산 환경에서 LLM 추론 모니터링(2026): vLLM, TGI, llama.cpp용 Prometheus 및 Grafana
프로메테우스와 그라파나를 사용하여 LLM 모니터링하기
LLM 추론은 “단순한 API처럼” 보일 수 있지만, 지연 시간이 급격히 증가하고 대기열이 다시 쌓이기 시작하며, GPU가 95% 메모리 사용률에 도달하면서도 명확한 설명이 없을 때 문제가 발생합니다.
프로메테우스와 그라파나를 사용하여 LLM 모니터링하기
LLM 추론은 “단순한 API처럼” 보일 수 있지만, 지연 시간이 급격히 증가하고 대기열이 다시 쌓이기 시작하며, GPU가 95% 메모리 사용률에 도달하면서도 명확한 설명이 없을 때 문제가 발생합니다.

2026년 1월 인기 Go 레포지토리
Go 생태계는 AI 도구, 자체 호스팅 애플리케이션, 개발자 인프라 등 혁신적인 프로젝트와 함께 계속해서 성장하고 있습니다. 이 개요는 이 달에 GitHub에서 가장 인기 있는 Go 저장소에 대한 분석을 제공합니다.

로컬 LLM을 위한 자체 호스팅형 ChatGPT 대안
Open WebUI는 대규모 언어 모델과 상호 작용할 수 있는 강력하고 확장성이 뛰어난 자체 호스팅 웹 인터페이스입니다.

메لبourn의 2026년 필수 기술 일정
멜버른의 기술 커뮤니티는 2026년에도 소프트웨어 개발, 클라우드 컴퓨팅, AI, 사이버 보안, 그리고 신기술 등 다양한 분야에 걸쳐 인상적인 컨퍼런스, 미팅, 워크숍이 진행되며 계속해서 번영하고 있습니다.
OpenAI API를 활용한 빠른 LLM 추론
vLLM은 UC Berkeley의 Sky Computing Lab에서 개발한 대규모 언어 모델(LLM)을 위한 고성능, 메모리 효율적인 추론 및 서빙 엔진입니다.

린터와 자동화로 Go 코드 품질을 완벽하게 관리하세요.
현대적인 Go 개발은 엄격한 코드 품질 기준을 요구합니다. Go용 린터는 코드가 프로덕션에 도달하기 전에 버그, 보안 취약점, 스타일 불일치를 자동으로 감지합니다.

Go 마이크로서비스를 사용하여 견고한 AI/ML 파이프라인을 구축하세요.
AI 및 머신러닝 워크로드가 점점 복잡해지면서, 견고한 오케스트레이션 시스템의 필요성이 더욱 커졌습니다. Go의 간결성, 성능, 동시성은 ML 파이프라인의 오케스트레이션 레이어를 구축하는 데 이상적인 선택이 됩니다. 모델 자체가 파이썬으로 작성되어 있더라도 말이죠.

예산 하드웨어에 오픈 모델을 사용하여 기업용 AI를 배포하세요.
AI의 민주화 시대가 도래했습니다.
Llama 3, Mixtral, Qwen과 같은 오픈소스 LLM이 이제는 전용 모델과 경쟁할 수 있을 정도로 발전했으며, 팀은 소비자 하드웨어를 사용하여 강력한 AI 인프라를 구축할 수 있습니다. 이는 비용을 절감하면서도 데이터 프라이버시와 배포에 대한 완전한 통제를 유지할 수 있습니다.

프로메테우스를 사용하여 견고한 인프라 모니터링을 설정하세요.
프로메테우스 는 클라우드 네이티브 애플리케이션 및 인프라를 모니터링하는 데 facto 표준이 되었으며, 메트릭 수집, 쿼리, 시각화 도구와의 통합을 제공합니다.
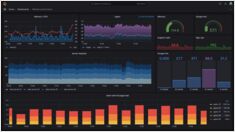
모니터링 및 시각화를 위한 Grafana 설정 방법 정리
Grafana은 메트릭, 로그, 트레이스를 시각화하여 실행 가능한 통찰을 제공하는 모니터링 및 관찰 플랫폼으로, 시각적으로 인상적인 시각화를 통해 리딩 오픈소스 플랫폼입니다.

Helm 패키지 관리와 함께하는 Kubernetes 배포
Helm은 전통적인 운영 체제에서 익숙한 패키지 관리 개념을 도입하여 Kubernetes 애플리케이션 배포를 혁신적으로 바꾸었습니다.

순차적 확장 및 지속 가능한 데이터와 함께 상태 있는 앱 배포
Kubernetes StatefulSets은 안정적인 정체성, 지속 가능한 저장소, 순서 있는 배포 패턴이 필요한 상태가 있는 애플리케이션을 관리하는 데 이상적인 솔루션입니다. 데이터베이스, 분산 시스템, 캐싱 레이어와 같은 필수적인 작업에 사용됩니다.

완전한 보안 가이드 - 정지 상태, 전송 중, 실행 중 데이터
데이터가 귀중한 자산일 때, 이를 보호하는 것이 지금까지보다 더 중요해졌습니다. 정보가 생성되는 순간부터 폐기되는 순간까지, 그 여정은 저장, 전송, 또는 활발히 사용되는 동안 위험에 노출될 수 있습니다. 저장, 전송, 또는 활발히 사용하는 동안 데이터는 다양한 위험에 직면하게 됩니다.
생산 환경에 적합한 서비스 메시지 배포 - Istio vs Linkerd
Istio와 Linkerd를 사용하여 서비스 메시지 아키텍처를 구현하고 최적화하는 방법을 알아보세요. 이 가이드는 배포 전략, 성능 비교, 보안 구성, 그리고 프로덕션 환경을 위한 최고의 실천 방법을 다룹니다.

홈랩 클러스터에 little k3s 쿠버네티스 설치
3노드 K3s 클러스터의 설치 단계별 가이드를 아래에 제공합니다.
이 가이드는 물리 서버(1 마스터 + 2 워커)에서 실행되는
**3노드 K3s 클러스터 설치**에 대한 것입니다.

쿠버네티스 변종에 대한 매우 짧은 개요
자체 호스팅 Kubernetes(self-hosting Kubernetes) 분포를 비교하여, 베어메탈 또는 홈 서버에 호스팅할 때 설치 용이성, 성능, 시스템 요구사항, 기능 세트에 초점을 맞추고 있습니다.