Modellrouting: Stop met het gebruik van één model voor alles
Het juiste model voor de juiste taak.
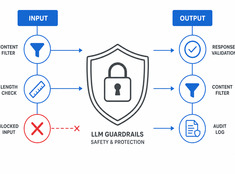
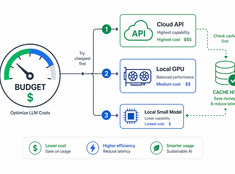
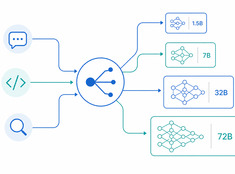
Het draaien van een model met 70 miljard parameters om een e-mail van 200 woorden samen te vatten, is zonde van de middelen. Het gebruiken van een model van 3 miljard parameters om productiecode te reviewen, is roekeloos. De meeste systemen zitten ergens daar tussenin — en daar komt modelrouting om de hoek kijken.