

LLM-kosten verlagen: strategieën voor tokenoptimalisatie
Verminder LLM-kosten met 80% dankzij slimme tokenoptimalisatie
Tokenoptimalisatie is de cruciale vaardigheid die kostenefficiënte LLM-toepassingen scheidt van budgetverslindende experimenten.
Verminder LLM-kosten met 80% dankzij slimme tokenoptimalisatie
Tokenoptimalisatie is de cruciale vaardigheid die kostenefficiënte LLM-toepassingen scheidt van budgetverslindende experimenten.

Uw foto's op een zelfgehoste AI-gedreven back-up
Immich is een revolutionaire open-source, zelfgehost oplossing voor het beheren van foto’s en video’s die je volledige controle geeft over je herinneringen. Met functies die concurreren met Google Photos - waaronder AI-gestuurde gezichtsherkenning, slimme zoekfuncties en automatische mobiele back-up - terwijl je data privé en veilig blijft op je eigen server.

GPT-OSS 120b benchmarks op drie AI-platforms
Ik vond enkele interessante prestatietests van GPT-OSS 120b die draaien op Ollama over drie verschillende platforms: NVIDIA DGX Spark, Mac Studio, en RTX 4080. De GPT-OSS 120b model uit de Ollama bibliotheek weegt 65 GB, wat betekent dat het niet past in de 16 GB VRAM van een RTX 4080 (of de nieuwere RTX 5080).

Maak MCP-servers voor AI-assistenten met Python-voorbeelden
De Model Context Protocol (MCP) is revolutionair voor de manier waarop AI-assistenten met externe gegevensbronnen en tools interacteren. In deze gids bespreken we hoe je MCP-servers in Python kunt bouwen, met voorbeelden gericht op webzoekfuncties en web scraping.

Snelle verwijzing naar Docker Model Runner-commands
Docker Model Runner (DMR) is de officiële oplossing van Docker voor het lokaal uitvoeren van AI-modellen, geïntroduceerd in april 2025. Deze cheatsheet biedt een snelle verwijzing naar alle essentiële opdrachten, configuraties en beste praktijken.

Vergelijk Docker Model Runner en Ollama voor lokale LLM
Het uitvoeren van grote taalmodellen (LLMs) lokaal is steeds populairder geworden vanwege privacy, kostcontrole en offlinefunctionaliteiten. Het landschap is aanzienlijk veranderd in april 2025 toen Docker Docker Model Runner (DMR) introduceerde, hun officiële oplossing voor AI-modellering.

ASIC's en aangepast silicium verhogen de snelheid en efficiëntie van LLM-inferentie.
De toekomst van AI draait niet alleen om slimmer [modellen](https://www.glukhov.org/nl/rag/embeddings/qwen3-embedding-qwen3-reranker-on-ollama/ “Qwen3 embedding en reranker modellen - state-of-the-art prestaties). Het gaat ook om silicium dat aansluit op de manier waarop deze modellen daadwerkelijk worden aangeboden. Gespecialiseerde hardware voor LLM-inferentie volgt een pad dat doet denken aan de verschuiving in Bitcoin-mining van GPUs naar doelgerichte ASICs, maar met strengere beperkingen omdat modellen en precisie-formules voortdurend evolueren.

Beschikbaarheid, daadwerkelijke retailprijzen in zes landen en een vergelijking met de Mac Studio.
NVIDIA DGX Spark is een feit, verkrijgbaar vanaf 15 oktober 2025, en is gericht op CUDA-ontwikkelaars die lokale LLM-werklasten nodig hebben met een geïntegreerde NVIDIA AI-stack. De US MSRP bedraagt $3.999; de retailprijs in UK/DE/JP is hoger door BTW en kanaalkosten. Publieke stickerprijzen voor AUD/KRW zijn nog niet algemeen gepubliceerd.

Integreer Ollama met Go: SDK-gids, voorbeelden en productiebest practices.
Deze gids biedt een uitgebreid overzicht van beschikbare Go SDKs voor Ollama en vergelijkt hun functionaliteiten.

Vergelijking van snelheid, parameters en prestaties van deze twee modellen
Hieronder volgt een vergelijking tussen Qwen3:30b en GPT-OSS:20b, met de nadruk op instructievolging en prestatieparameters, specificaties en snelheid.

Niet erg aangenaam.
Ollama’s GPT-OSS modellen hebben herhalende problemen met het verwerken van gestructureerde uitvoer, vooral wanneer ze worden gebruikt met frameworks zoals LangChain, OpenAI SDK, vllm en anderen.

Enkele manieren om gestructureerde output van Ollama te krijgen
Grote Taalmodellen (LLM’s) zijn krachtig, maar in productieomgevingen willen we zelden vrij tekst. In plaats daarvan willen we voorspelbare data: attributen, feiten of gestructureerde objecten die je in een applicatie kunt laden. Dat is Gestructureerde Output van LLM’s.

Mijn eigen test van ollama model planning
Hier vergelijk ik hoeveel VRAM de nieuwe versie van Ollama toewijst aan het model hoeveel VRAM nieuwe versie van Ollama toewijst aan het model met de vorige Ollama-versie. De nieuwe versie is erger.

Mijn visie op de huidige staat van Ollama-ontwikkeling
Ollama is snel geworden tot een van de meest populaire tools om LLMs lokaal uit te voeren. Zijn eenvoudige CLI en gestroomlijnde modelbeheer hebben het tot de favoriete keuze gemaakt voor ontwikkelaars die willen werken met AI-modellen buiten de cloud.

Korte overzicht van de meest opvallende UI's voor Ollama in 2025
Locally geïnstalleerde Ollama maakt het mogelijk om grote taalmodellen op je eigen computer te draaien, maar het gebruik ervan via de opdrachtnaam is niet gebruikersvriendelijk. Hieronder vind je verschillende open-source projecten die ChatGPT-stijl interfaces bieden die verbinding maken met een lokale Ollama.
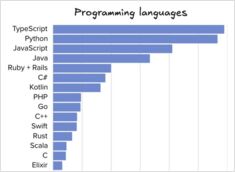
Vergelijking van software-engineering-tools en -talen
Het Pragmatic Engineer letter verscheen een paar dagen geleden met een enquête over de populariteit van programmeertalen, IDEs, AI-tools en andere gegevens voor het midden van 2025.