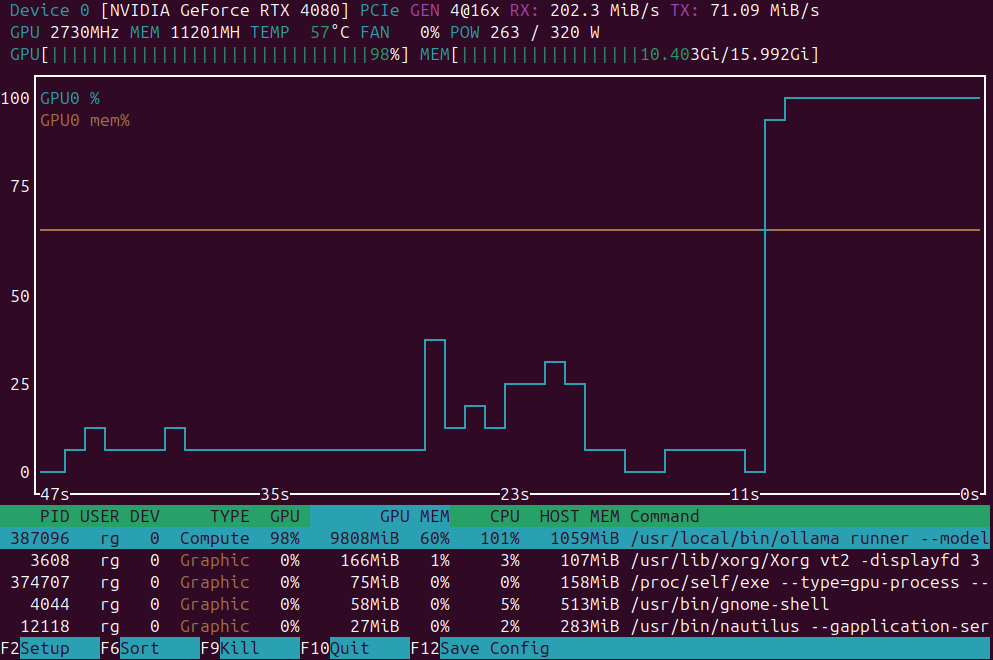
GPU-onsteunigheid van NVIDIA toevoegen aan Docker Model Runner
Stel GPU-acceleratie in voor Docker Model Runner met ondersteuning voor NVIDIA CUDA
Docker Model Runner is Docker’s officiële tool om AI-modellen lokaal uit te voeren, maar NVIDIA GPU-acceleratie inschakelen in Docker Model Runner vereist specifieke configuratie.