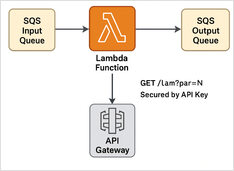
Airtable — ограничения бесплатного плана, API, вебхуки, Go и Python.
Airtable лучше всего рассматривать как платформу для создания приложений с низким уровнем кода, построенную вокруг совместного “базоподобного” интерфейса таблиц - отличное решение для быстрого создания операционных инструментов (внутренние трекеры, легковесные CRM, контентные конвейеры, очереди оценки ИИ), где неразработчикам нужен дружелюбный интерфейс, а разработчикам - API для автоматизации и интеграции.
Learn how to monitor LLM inference servers (vLLM, Hugging Face TGI, llama.cpp) using Prometheus and Grafana. This article covers what to measure, how to expose and scrape /metrics, example PromQL queries for p95 latency and tokens/sec, ready-to-use Docker Compose and Kubernetes manifests, Grafana dashboard provisioning, alerting, and real-world troubleshooting.
OpenClaw — это самоуправляемый AI-ассистент, предназначенный для работы с локальными LLM-движками, такими как Ollama, или с облачными моделями, такими как Claude Sonnet.
AWS S3 остается “стандартным” базовым решением для объектного хранения: это полностью управляемая, сильно согласованная система, разработанная для чрезвычайно высокой долговечности и доступности.
Garage и MinIO — это самонастраиваемые альтернативы, совместимые с S3: Garage предназначен для легковесных, геораспределенных кластеров малого и среднего размера, в то время как MinIO делает акцент на широком покрытии API S3 и высокой производительности в крупных развертываниях.
Стратегия полной наблюдаемости для инференса LLM и приложений LLM
Build an end-to-end observability strategy for LLM inference and LLM applications: what to measure, how to instrument, which tools to use, how to control cardinality and sampling, and how to deploy and scale the telemetry pipeline securely.
Strategic guide to hosting large language models locally with Ollama, llama.cpp, vLLM, or in the cloud. Compare tools, performance trade-offs, and cost considerations.
Управляйте данными и моделями с помощью саморазмещаемых ЛЛМ
Самостоятельное размещение LLM позволяет контролировать данные, модели и выводы — это практический путь к суверенитету ИИ для команд, предприятий и стран.
Стратегии кэширования Hugo (https://www.glukhov.org/ru/post/2025/11/hugo-caching-strategies/ “Стратегии кэширования Hugo”) являются ключевыми для максимизации производительности вашего статического генератора сайтов. Хотя Hugo генерирует статические файлы, которые изначально быстры, правильное кэширование на нескольких уровнях может значительно улучшить время сборки, снизить нагрузку на сервер и повысить пользовательский опыт.
Специализированные чипы ускоряют и удешевляют выводы ИИ
Будущее ИИ не ограничивается более умными моделями - это также вопрос более умного кремния. Специализированное оборудование для инференса ЛЛМ приводит к революции, аналогичной переходу майнинга биткоинов к ASIC.
Приблизительные оценки стоимости хостинга по сравнению с подпиской.
Вот краткая информация о Write.as / WriteFreely - как это вписывается в fediverse, где можно получить управляемый хостинг, как выглядит тенденция использования, и как развернуть самостоятельно (плюс примерные расчеты стоимости).
Отличный инструмент для платформенной разработки на AWS
AWS Cloud Development Kit (AWS CDK)
— это фреймворк, который позволяет определять и развертывать облачную инфраструктуру с использованием привычных языков программирования, таких как
TypeScript,
Python,
Java и
Go.
Выбор лучшего варианта Kubernetes для нашего домашнего лабораторного стенда
Я сравниваю варианты самонастраиваемых Kubernetes, подходящие для хоумлаба на основе Ubuntu с 3 узлами (16 ГБ ОЗУ, 4 ядра каждый), с акцентом на простоте установки и обслуживания, поддержке постоянных томов и LoadBalancers.