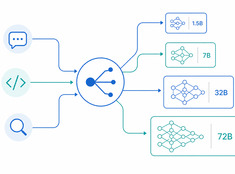
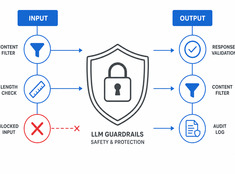
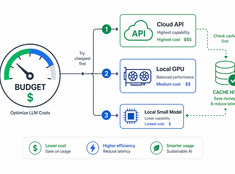
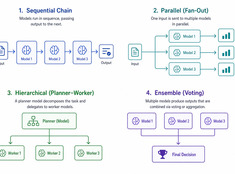
Digitale Gärten: Wissen wachsen lassen statt es nur zu veröffentlichen
Verbreiten Sie wachsendes Wissen, nicht nur Beiträge.
Das vorherrschende Modell zur Veröffentlichung von Wissen im Internet hat sich seit den frühen 2000er Jahren kaum verändert: Etwas schreiben, polieren, veröffentlichen und dann weiterziehen.