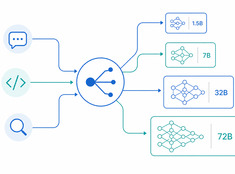
Modell-Routing: Verwenden Sie nicht ein Modell für alles
Das richtige Modell für die richtige Aufgabe.
Das Ausführen eines Modells mit 70 Milliarden Parametern, um eine 200-Wörter-E-Mail zusammenzufassen, ist verschwenderisch. Das Ausführen eines 3-Milliarden-Parameter-Modells zur Überprüfung von Produktionscode ist fahrlässig. Die meisten Systeme liegen irgendwo dazwischen – und genau hier kommt das Modell-Routing ins Spiel.