

LLM Wiki Maintenance: Drift, Contradictions and Review
Keep compiled knowledge trustworthy
An LLM Wiki fails when old facts remain plausible, contradictions become polished, and generated summaries drift from their sources.
Keep compiled knowledge trustworthy
An LLM Wiki fails when old facts remain plausible, contradictions become polished, and generated summaries drift from their sources.

AI GPU comparison across three vendors
The AI hardware landscape has shifted significantly in 2026, with NVIDIA, AMD, and Intel all competing for developers who need GPUs capable of running local large language models and AI inference workloads.

Headless Hermes server with remote desktop access
Running Hermes Agent on a headless server while connecting from a desktop client on another machine requires two server processes and a single client connection.
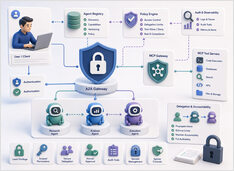
Protocol security is who may act, not the model.
Prompt injection gets most of the security attention in LLM systems, and it deserves attention, but it is not the whole problem once agents start calling tools and delegating work to other agents.
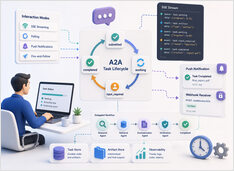
Long-running A2A tasks outlive chat sessions.
Most AI agent demos still behave like chat completions with extra steps: you send a prompt, wait a few seconds, and get an answer back in one response.

Faster LLM inference without quality loss - a practical guide
A 70B model generates one token per forward pass, and each pass reloads weights from VRAM, computes attention across the context, and synchronizes memory. Between tokens, the GPU sits idle while it waits for sequential dependencies to resolve.

A2A is not dead. It is just not universal.
Google’s Agent2Agent protocol, usually shortened to A2A, had a strange first year.

Reliable polling patterns for AI agents.
Polling agents are one of the least glamorous parts of AI assistant architecture, but they are also one of the most useful.

MCP gives agents tools. A2A gives agents peers.
AI agent architecture is starting to split into two layers.

A2A turns agents into network peers.
The A2A Protocol, short for Agent2Agent Protocol, is an open standard for communication between independent AI agent systems.
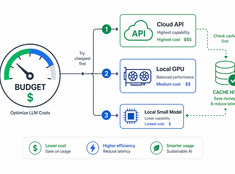
Spend tokens where they actually matter.
LLM costs scale linearly with usage. A system processing 10,000 requests a day at $0.01 per request costs $100 daily — $365 a year. At enterprise scale, that’s over $10,000.
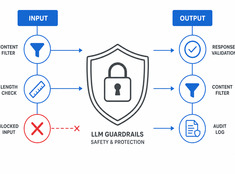
Control the risk, not just the model.
LLMs are unpredictable. They hallucinate, leak data, generate harmful content, or refuse legitimate requests. Guardrails constrain model behavior without sacrificing capability.
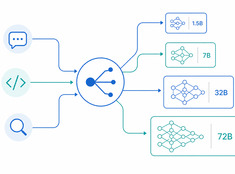
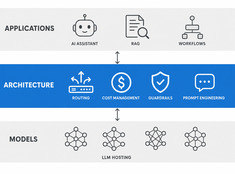
The right model for the right task.
Running a 70B parameter model to summarize a 200-word email is wasteful. Running a 3B model to review production code is reckless. Most systems live somewhere in between — and that’s where model routing comes in.
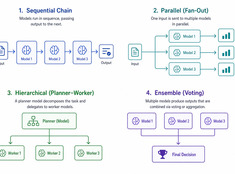
Pick the simplest pattern that works.
Single-model systems are simple. Multi-model systems are powerful. The challenge isn’t choosing models — it’s designing the architecture that orchestrates them.

Working, structured, and retrieval memory for assistants.
Memory turns assistants from reactive to persistent, but it is also where many systems quietly rot. Surveys argue the short-term versus long-term split is no longer enough for modern agent memory; OpenAI and LangGraph SDKs point to a simpler stack — working memory, durable state, and retrieval.