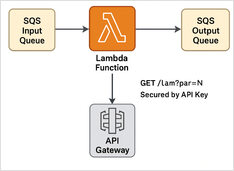
LLM ASICs and specialized inference chips (why they matter)
ASICs and custom silicon push LLM inference speed and efficiency
The future of AI is not only about smarter models. It is also about silicon that matches how those models are actually served. Specialized hardware for LLM inference is following a path reminiscent of Bitcoin mining’s move from GPUs to purpose-built ASICs, only with harder constraints because models and precision recipes keep evolving.