

「観測性チームのための現代的アラートシステム設計」
アラート通知はノイズを流すための仕組みではなく、対応のためのシステムである
アラートは、監視機能として語られることが多すぎます。 その枠組みは便利ですが、真の問題を隠してしまいます。
アラート通知はノイズを流すための仕組みではなく、対応のためのシステムである
アラートは、監視機能として語られることが多すぎます。 その枠組みは便利ですが、真の問題を隠してしまいます。

「OpenCode」のインストール、設定、および使用方法
ローカル推論には、llama.cpp を使い続けています。Ollama や他のツールが抽象化している部分を自分で制御できるためであり、単に「動く」だけでなく、GGUF モデルを llama-cli で対話的に実行したり、llama-server で OpenAI 互換の HTTP API を公開したりするのが簡単だからです。

Prometheus と Grafana を用いた LLM の監視
LLM の推論は「ただの API」のように見えますが、レイテンシが急増し、キューが backlog して、GPU のメモリ使用率が 95% に達しても明確な説明ができない状況に直面した際に、その真の姿が明らかになります。

LLM推論およびLLMアプリケーションのためのエンドツーエンドの可視化戦略
LLM(大規模言語モデル)システムは、従来のAPIモニタリングでは検知できない方法で失敗します。キューが静かに埋め尽くされ、CPUが忙しい状態になる遥か前にGPUメモリが飽和し、レイテンシはアプリケーションレイヤーではなくバッチ処理レイヤーで急増します。

本番環境のメトリクス、ダッシュボード、ログ、およびアラート機能 — Prometheus、Grafana、Kubernetes、およびAIワークロード
可観測性は、信頼性の高い本番環境システムの基盤です。
メトリクス、ダッシュボード、アラートがないと、Kubernetesクラスターは状態が不安定になり、AIワークロードはサイレントに失敗し、レイテンシの劣化はユーザーからの苦情があるまで気づかれません。

プロメテウスで堅牢なインフラストラクチャのモニタリングを構築しましょう
Prometheus は、クラウドネイティブなアプリケーションとインフラストラクチャのモニタリングにおいて事実上の標準となり、メトリクスの収集、クエリ、可視化ツールとの統合を提供しています。
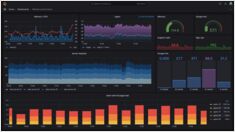
グラファナの設定をマスターしてモニタリングと可視化を実現しましょう
Grafana は、メトリクス、ログ、トレースを視覚的に表現し、アクション可能なインサイトに変換するための、監視および観測性のための主要なオープンソースプラットフォームです。