

LLM Wikiの保守:ドリフト、矛盾、およびレビュー
コンパイルされた知識の信頼性を確保する
LLMウィキは、古い事実が依然として妥当に見えるようになり、矛盾が磨き上げられ、生成された要約が元々の情報源から逸脱した際に失敗します。
コンパイルされた知識の信頼性を確保する
LLMウィキは、古い事実が依然として妥当に見えるようになり、矛盾が磨き上げられ、生成された要約が元々の情報源から逸脱した際に失敗します。

3社によるAI GPUの比較
2026年、AIハードウェアの状況は大きく変化しました。NVIDIA、AMD、Intelの各社が、ローカル環境で大型言語モデル(LLM)やAI推論ワークロードを実行できるGPUを必要とする開発者を獲得するため、激しい競争を繰り広げています。
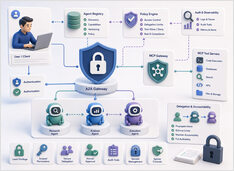
プロトコルセキュリティはモデルではなく、誰が実行できるか(誰が操作を行えるか)を定義するものです。
LLMシステムにおけるセキュリティの関心は、プロンプトインジェクションに最も集中していますが、それは確かに注目を集めるべきものです。しかし、エージェントがツールを呼び出し、他のエージェントに作業を委任し始めると、それは問題の一部に過ぎなくなります。
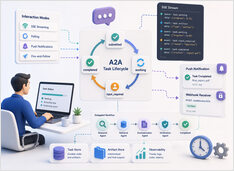
長期実行されるA2Aタスクは、チャットセッションの終了後も継続して実行されます。
ほとんどのAIエージェントのデモは、追加のステップを伴うチャット補完のように振る舞います。プロンプトを送信し、数秒待ってから、1つのレスポンスとして回答を受け取ります。

質の低下なしでLLM推論を高速化する方法 — 実践ガイド
70Bパラメータのモデルは1回のフォワードパスで1つのトークンを生成し、各パスではVRAMから重みを読み込み、コンテキスト全体でアテンションを計算し、メモリを同期します。トークンの間では、逐次依存関係が解決されるのを待つ間、GPUはアイドル状態になります。

仕様書こそが唯一の信頼情報源であり、単なる補助文書ではない。
仕様駆動型開発(Spec-Driven Development)は、ソフトウェアエンジニアが以前から追求してきたものの、努力に見合う成果が得られなくなった際に棚上げされてきたアイデアの一つです。

仕様を唯一の正解とするのか、それとも遅い儀式とするのか
仕様駆動型開発(SDD)は、2026年において「バイブコーディング(Vibe Coding)の逸脱」に対する真面目な開発者の回答として登場しました。

A2Aは死んでいません。単に普遍的ではないだけです。
GoogleのAgent2Agentプロトコル、一般的にA2Aと略されるこの規格は、最初の1年間で奇妙な展開をみせました。

AIエージェントのための信頼性の高いポーリングパターン
ポーリングエージェントは、AIアシスタントのアーキテクチャの中で最も華やかではない部分の一つですが、同時に最も有用な部分の一つでもあります。

MCPはエージェントにツールを提供し、A2Aはエージェントにピア(対等なパートナー)を提供します。
AIエージェントアーキテクチャは、2つのレイヤーに分割されつつあります。

「A2Aはエージェントをネットワークピアに変換します。」
Agent2Agentプロトコルの略称であるA2Aプロトコルは、独立したAIエージェントシステム間の通信のためのオープン標準です。
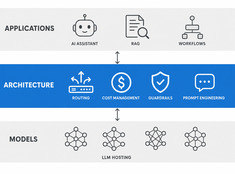
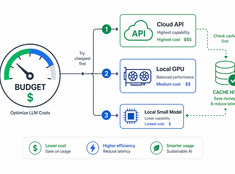
本当に重要な場所でトークンを活用しましょう。
LLMのコストは利用量に対して線形に比例して増加します。1日10,000リクエスト、1リクエストあたり0.01ドルで処理するシステムの場合、日額コストは100ドル、年間では365ドルになります。エンタープライズ規模では、それが1万ドルを超えます。
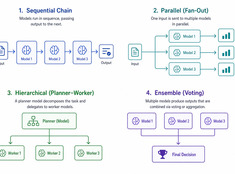
「機能する最もシンプルなパターンを選びましょう。」
シングルモデルのシステムはシンプルです。マルチモデルのシステムは強力です。課題はモデルを選ぶことではなく、それらを調整するアーキテクチャを設計することにあります。
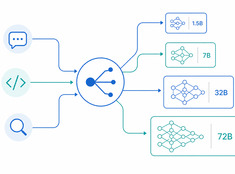
適切なタスクに最適なモデル。
700億パラメータのモデルを使って200語のメールを要約するのは無駄です。30億パラメータのモデルで本番環境のコードレビューを行うのは無謀です。多くのシステムはその中間に位置しており、そこがモデルルーティングの登場シーンです。
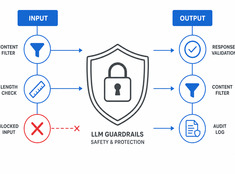
管理すべきはモデルではなく、リスクです。
LLM(大規模言語モデル)は予測不可能です。幻覚(ハルシネーション)を起こし、データを漏洩させ、有害なコンテンツを生成したり、正当なリクエストを拒否したりします。ガードレール(防護策)は、機能を損なわずにモデルの動作を制限します。