

Linux サービスにおける Podman Quadlet と Docker Compose の比較
適切なコンテナワークフローを選択してください。
Docker ComposeとPodman Quadletは重複する問題を解決しますが、異なる設計理念から来ています。どちらを選ぶかは、アプリケーションスタックとして考えるか、Linuxサービスとして考えるかに依存します。
適切なコンテナワークフローを選択してください。
Docker ComposeとPodman Quadletは重複する問題を解決しますが、異なる設計理念から来ています。どちらを選ぶかは、アプリケーションスタックとして考えるか、Linuxサービスとして考えるかに依存します。

リモートデスクトップアクセスに対応したヘッドレスHermesサーバー
ヘッドレスサーバーで Hermes エージェントを実行し、別のマシンのデスクトップクライアントから接続するには、2つのサーバープロセスと1つのクライアント接続が必要です。
systemd によって管理される起動時の Docker Compose
Linux サーバー上の Docker Compose は、ブート時に起動し、シャットダウン時にクリーンに停止し、手動介入なしで再起動に耐えられるべきです。

Ubuntuで適切なDockerのインストールパスを選択してください。
Ubuntu に Docker をインストールするのは本来シンプルであるはずですが、実際には複数の「Docker 関連」の選択肢が同じコマンド名を巡って競合しており、それぞれ異なるパッケージ構成、アップグレード動作、セキュリティへの影響を持っています。

AIエージェントのための信頼性の高いポーリングパターン
ポーリングエージェントは、AIアシスタントのアーキテクチャの中で最も華やかではない部分の一つですが、同時に最も有用な部分の一つでもあります。
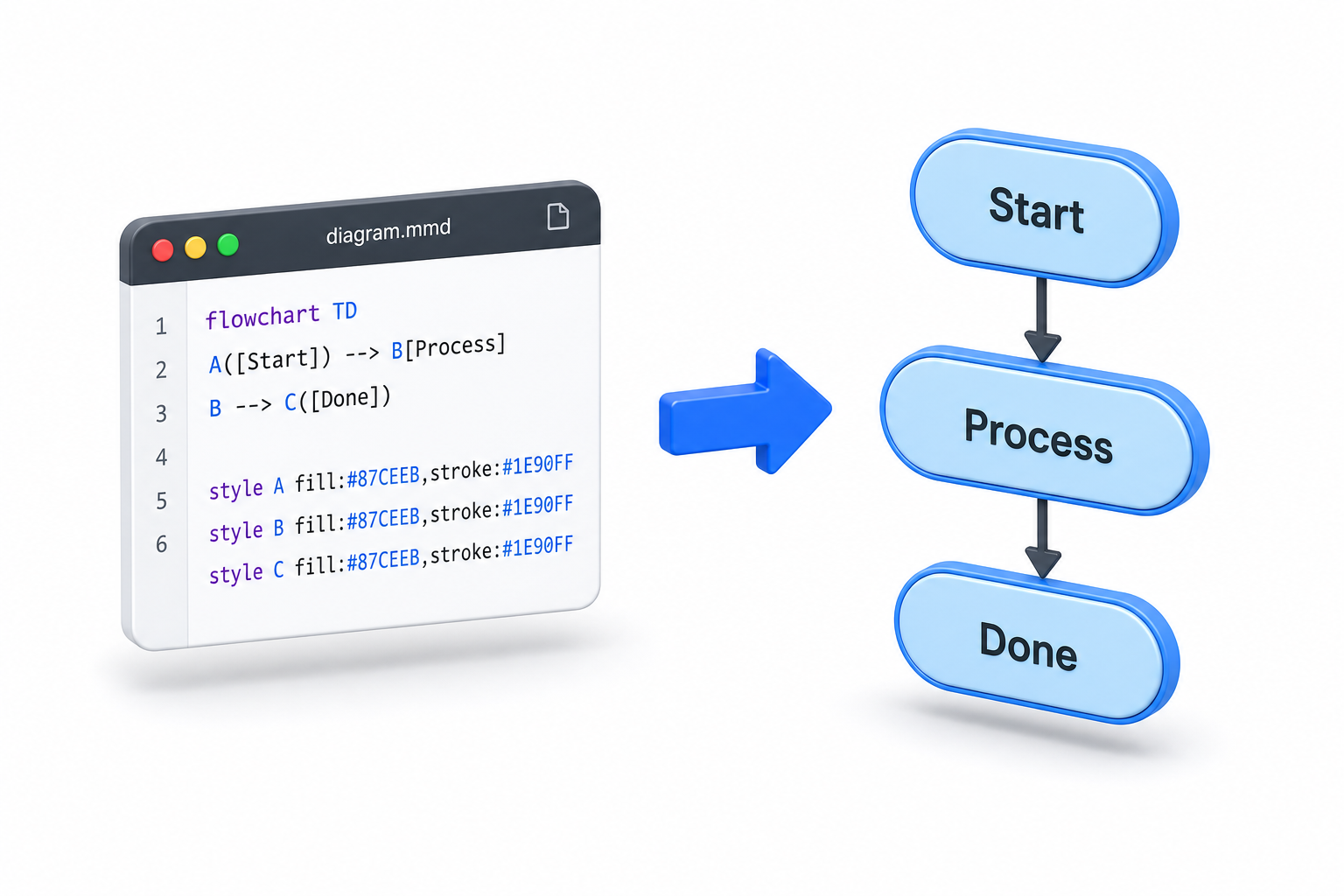
コードによる図解、トラブルなし。
Mermaidは、キャンバス上でボックスをドラッグするよりも、図をテキストとして記述することを好む人々のためのテキストベースの図作成ツールです。Markdownのような構文を使用して、フローチャート、シーケンス図、クラス図、状態機械図、タイムライン、ガントチャート、エンティティ関係図などを記述します。

本格的なアシスタントは実際にどのように構築されているのか
本番環境向けのAIアシスタントは「プロンプト付きのLLM」ではありません。それは意図を受け取り、状態を保持し、いつ取得したり実行したりするかを決定し、障害のデバッグに必要なランタイムの詳細を公開するシステムです。

llama-serverを停止せずにVRAMを解放する方法
llama.cpp ラーターモード は、llama-server における数年間で最も有用な変更の一つです。これにより、ローカルLLM運用者は、Ollamaで期待されるようなモデル管理体験に近いものをようやく手に入れることができました。同時に、llama-server を使い続ける価値がある生のパフォーマンスと低レベルの制御も維持されています。

セルフホスト型LLMにおけるHermesカーンボードの負荷を制御する
Hermes AgentにはKanbanスタイルのボードとHermes Gatewayが標準で搭載されていますが、一度に多数のタスクがディスパッチされると、セルフホスト型のLLMが過負荷状態に陥る可能性があります。

リスタートなしでLLMの提供と入れ替えを実現します。
長らく llama.cpp には顕著な制限がありました。1つのプロセスで1つのモデルしか提供できず、モデルの切り替えには再起動が必要だったのです。

まずはプラグイン。スキルの名称を簡潔に。
この記事は、チャネル、モデルプロバイダー、ツール、音声、メモリ、メディア、Web 検索、その他ランタイムの表面機能などを追加するネイティブゲートウェイパッケージであるOpenClaw プラグインについて解説します。

開発者向け「Hermes Agent」のインストールとクイックスタート
Hermes Agentは、ローカルマシンや低コストのVPS上で動作する自己ホスト型でモデル非依存のAIアシスタントであり、ターミナルおよびメッセージングインターフェースを介して動作し、繰り返し行うタスクを再利用可能なスキルに変換することで、時間とともに性能を高めていきます。

公開ポートを使用しないリモート Ollama アクセス
Ollama は、ローカルデーモンとして扱われるときに最も快適に動作します。CLI とアプリケーションがループバック HTTP API と通信し、残りのネットワークにはその存在が知られない状態です。

GPU および永続性を備えた Compose ファーストの Ollama サーバー。
Ollama は、メタル(物理マシン)上で非常に良好に動作します。それをサービスとして扱うと、さらに興味深くなります。安定したエンドポイント、固定されたバージョン、永続的なストレージ、そして GPU が利用可能か不可かの明確な状態が確保されます。

ストリーミング応答を破綻させずに HTTPS で Ollama を利用する。
リバースプロキシの背後で Ollama を実行することは、HTTPS、オプションのアクセス制御、予測可能なストリーミング動作を実現する最も簡単な方法です。

ステートフルストリーミング、チェックポイント、K8s、PyFlink、Go。
Apache Flink は、有界および無界のデータストリームに対して状態付きの計算を行うためのフレームワークです。