
オープンウェブUI: 自己ホスト型LLMインターフェース
ローカルLLM用のセルフホスト型ChatGPT代替ソフト
Open WebUIは、拡張性が高く、機能豊富な自己ホスト型のウェブインターフェースで、大規模言語モデルとやり取りするのに最適です。
ローカルLLM用のセルフホスト型ChatGPT代替ソフト
Open WebUIは、拡張性が高く、機能豊富な自己ホスト型のウェブインターフェースで、大規模言語モデルとやり取りするのに最適です。
OpenAI API を使用した高速なLLM推論
vLLM は、UC BerkeleyのSky Computing Labが開発した、大規模言語モデル(LLM)向けの高スループットでメモリ効率の良い推論およびサービングエンジンです。
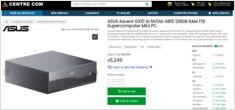
今やオーストラリアの小売業者から実際のAUD価格が提供されています。
NVIDIA DGX Spark (GB10 Grace Blackwell)は オーストラリアで今すぐ購入可能 の主要PC小売店で在庫あり。
グローバルDGX Sparkの価格と入手方法を ご存知の方は、オーストラリアの価格がストレージ構成や小売店によって 6,249〜7,999オーストラリアドル と幅があることをご存知でしょう。

AI生成コンテンツの検出に関する技術ガイド
AI生成コンテンツの増加により、新たな課題が生じています。それは、本物の人の書き方と「AIスロップ」(https://www.glukhov.org/ja/post/2025/12/ai-slop-detection/ “AIスロップ”)を区別することです。AIスロップとは、低品質で大量生産された合成テキストのことです。

ローカルLLMでCogneeをテストする - 実際の結果
CogneeはPythonフレームワークで、LLMを使用してドキュメントから知識グラフを構築するためのものです。 しかし、これは自社ホストされたモデルと互換性があるのでしょうか?

BAML と Instructor を使用した型安全な LLM 出力
LLM(大規模言語モデル)を本番環境で使用する際には、構造化された、型安全な出力を得ることが極めて重要です。
BAMLおよびInstructorという2つの人気のあるフレームワークは、この問題に対して異なるアプローチを取ります。

LLMを自社でホストするCogneeについての考察
最適なLLMの選定は、グラフ構築の品質、幻覚率、ハードウェアの制約をバランスよく考慮する必要があります。
Cogneeは、Ollama](https://www.glukhov.org/ja/post/2024/12/ollama-cheatsheet/ “Ollama cheatsheet”)を通じて32B以上の低幻覚モデルで優れたパフォーマンスを発揮しますが、軽量な構成では中規模のオプションも利用可能です。
必須のショートカットとマジックコマンド
Jupyter Notebookの生産性を飛躍的に向上させるために、データサイエンスおよび開発体験を変革するための必須のショートカット、マジックコマンド、ワークフローのヒントをご活用ください。

PythonとOllamaを使ってAI検索エージェントを構築する
OllamaのPythonライブラリは、今やOLlama web searchのネイティブな機能を含んでいます。わずか数行のコードで、ローカルのLLMをインターネット上のリアルタイム情報を補完し、幻覚を減らし、正確性を向上させることができます。

RAGスタックに適したベクトルDBを選びましょう
正しいベクトルストアを選択することで、RAGアプリケーションの性能、コスト、拡張性が大きく左右されます。この包括的な比較では、2024年~2025年の最も人気のあるオプションをカバーしています。

GoとOllamaを使ってAI検索エージェントを構築する
OllamaのWeb検索APIは、ローカルLLMにリアルタイムのウェブ情報を補完する機能を提供します。このガイドでは、GoでのWeb検索の実装について、単純なAPI呼び出しからフル機能の検索エージェントまでの実装方法を示します。

12種類以上のツールでローカルLLMの展開をマスターする
ローカルでのLLMの展開は、開発者や組織がプライバシーの向上、レイテンシーの低減、AIインフラストラクチャの制御の強化を求めるにつれて、ますます人気になっています。

Goマイクロサービスを使用して堅牢なAI/MLパイプラインを構築しましょう
AIおよび機械学習(ML)ワークロードがますます複雑になるにつれて、強固なオーケストレーションシステムの必要性が高まっています。Goのシンプルさ、パフォーマンス、並行処理能力は、MLパイプラインのオーケストレーションレイヤーを構築する際に理想的な選択肢です。モデル自体がPythonで書かれている場合でも、Goは理想的な選択肢です。https://www.glukhov.org/ja/post/2025/11/go-microservices-for-ai-ml-orchestration-patterns/ “Go in ML orchestration pipelines”。

テキスト、画像、音声を共有された埋め込み空間に統一する
クロスモーダル埋め込みは、人工知能において画期的な進展をもたらし、統一された表現空間内で異なるデータタイプ間の理解と推論を可能にします。

予算のハードウェアでオープンモデルを使用して企業向けAIを展開
AIの民主化はここにあります。 Llama 3、Mixtral、QwenなどのオープンソースLLMが、今やプロプライエタリモデルと同等の性能を発揮するようになり、チームは消費者ハードウェアを使用して強力なAIインフラストラクチャを構築できるようになりました。これにより、コストを削減しながらも、データプライバシーやデプロイメントに関する完全なコントロールを維持することが可能です。

LongRAG、Self-RAG、GraphRAG - 次世代の技術
リトリーバル・オーガナイズド・ジェネレーション (RAG) は単純なベクトル類似性検索を超えています。 LongRAG、Self-RAG、GraphRAGはこれらの能力の最先端を代表しています。