

OpenHands コーディングアシスタントのクイックスタート:インストール、CLI フラグ、例
OpenHands CLI を数分でクイックスタート
OpenHands は、AI 駆動のソフトウェア開発エージェントのためのオープンソースでモデル非依存のプラットフォームです。 単なる自動補完ツールではなく、エージェントがコーディングパートナーのように振る舞うことを可能にします。
OpenHands CLI を数分でクイックスタート
OpenHands は、AI 駆動のソフトウェア開発エージェントのためのオープンソースでモデル非依存のプラットフォームです。 単なる自動補完ツールではなく、エージェントがコーディングパートナーのように振る舞うことを可能にします。

数分で LocalAI を使用して、OpenAI 互換 API をセルフホストできます。
LocalAI は、ご自身のハードウェア(ノート PC、ワークステーション、オンプレミスサーバー)上で AI ワークロードを実行できるように設計された、自己完結型でローカルファーストの推論サーバーです。これは、OpenAI API と互換性のある「差し替え可能な」APIとして動作します。

プロメテウスとグラファナでLLMをモニタリングする
LLMの推論は「単なるAPI」のように見えるが、レイテンシーが急激に増加し、キューが再び詰まり、GPUが95%のメモリ使用率で動いていても明らかに原因が分からないという状況に陥るまでには至らない。

ローカルに OpenClaw を Ollama でインストールする
OpenClawは、OllamaなどのローカルLLMランタイムや、Claude Sonnetなどのクラウドベースのモデルを使用して動作する、セルフホスト型のAIアシスタントです。

2026年1月の人気Goリポジトリ
Goエコシステムは、AIツール、セルフホストアプリケーション、開発者インフラにわたる革新的なプロジェクトとともに、ますます活気づいています。この概要では、今月のGitHub上位トレンドGoリポジトリについて分析します。

ローカルLLM用のセルフホスト型ChatGPT代替ソフトウェア
Open WebUI は、大規模言語モデルと対話するための強力で拡張性があり、機能豊富な自己ホスト型ウェブインターフェースです。
OpenAI API を活用した高速 LLM 推論
vLLM は、UC Berkeley の Sky Computing Lab によって開発された、大規模言語モデル(LLM)向けの高速スループットかつメモリエフィレントな推論およびサーバーエンジンです。

ローカルLLMを使用してCogneeをテストする - 実際の結果
CogneeはPythonフレームワークで、LLMを使用してドキュメントから知識グラフを構築します。 しかし、これはセルフホストされたモデルと互換性がありますか?

Compare the best local LLM hosting tools in 2026. API maturity, hardware support, tool calling, and real-world use cases.
LLMをローカルで実行することは、開発者、スタートアップ企業、さらには企業チームにとって現在実用的です。
しかし、正しいツールの選択 — Ollama、vLLM、LM Studio、LocalAI またはその他のツール — は、あなたの目的によって異なります:

リナーアと自動化でGoコードの品質をマスターしましょう
現代のGo開発は厳格なコード品質基準を要求しています。Go用のリントツールは、コードが本番環境に到達する前にバグやセキュリティの脆弱性、スタイルの不一致を自動検出します。

Goマイクロサービスを使用して堅牢なAI/MLパイプラインを構築しましょう
AIおよび機械学習(ML)ワークロードがますます複雑になるにつれて、強固なオーケストレーションシステムの必要性が高まっています。Goのシンプルさ、パフォーマンス、並行処理能力は、MLパイプラインのオーケストレーションレイヤーを構築する際に理想的な選択肢です。モデル自体がPythonで書かれている場合でも、Goは理想的な選択肢です。https://www.glukhov.org/ja/post/2025/11/go-microservices-for-ai-ml-orchestration-patterns/ “Go in ML orchestration pipelines”。

テキスト、画像、音声を共有された埋め込み空間に統一する
クロスモーダル埋め込みは、人工知能において画期的な進展をもたらし、統一された表現空間内で異なるデータタイプ間の理解と推論を可能にします。

予算のハードウェアでオープンモデルを使用して企業向けAIを展開
AIの民主化はここにあります。 Llama 3、Mixtral、QwenなどのオープンソースLLMが、今やプロプライエタリモデルと同等の性能を発揮するようになり、チームは消費者ハードウェアを使用して強力なAIインフラストラクチャを構築できるようになりました。これにより、コストを削減しながらも、データプライバシーやデプロイメントに関する完全なコントロールを維持することが可能です。

プロメテウスで堅牢なインフラストラクチャのモニタリングを構築しましょう
Prometheus は、クラウドネイティブなアプリケーションとインフラストラクチャのモニタリングにおいて事実上の標準となり、メトリクスの収集、クエリ、可視化ツールとの統合を提供しています。

Goの堅牢なエコシステムを使って、本番環境に適したREST APIを構築しましょう。
高性能な REST APIの構築(Goを使用) は、Google、Uber、Dropbox、そして多数のスタートアップでシステムを動かすための標準的なアプローチとなっています。
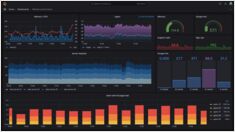
グラファナの設定をマスターしてモニタリングと可視化を実現しましょう
Grafana は、メトリクス、ログ、トレースを視覚的に表現し、アクション可能なインサイトに変換するための、監視および観測性のための主要なオープンソースプラットフォームです。