

16GB VRAM GPU上でOllamaを使用したLLMの性能比較
RTX 4080(16GB VRAM)でのLLM速度テスト
大規模言語モデルをローカルで実行すると、プライバシーの確保、オフラインでの使用が可能になり、APIコストはゼロになります。このベンチマークでは、RTX 4080上で動作する14のポピュラーなLLMs on Ollamaから期待できる性能が明らかになります。
RTX 4080(16GB VRAM)でのLLM速度テスト
大規模言語モデルをローカルで実行すると、プライバシーの確保、オフラインでの使用が可能になり、APIコストはゼロになります。このベンチマークでは、RTX 4080上で動作する14のポピュラーなLLMs on Ollamaから期待できる性能が明らかになります。
正しいターミナルを選んでLinuxワークフローを最適化しましょう
Linuxユーザーにとって最も重要なツールの一つは、端末エミュレータです。https://www.glukhov.org/ja/post/2026/01/terminal-emulators-for-linux-comparison/ “Linux端末エミュレータ比較”

今やオーストラリアの小売業者から実際のAUD価格が提供されています。
NVIDIA DGX Spark (GB10 Grace Blackwell)は オーストラリアで今すぐ購入可能 の主要PC小売店で在庫あり。
グローバルDGX Sparkの価格と入手方法を ご存知の方は、オーストラリアの価格がストレージ構成や小売店によって 6,249〜7,999オーストラリアドル と幅があることをご存知でしょう。

AIに最適な消費者向けGPUの価格 - RTX 5080およびRTX 5090
トップレベルの消費者向けGPUの価格を比較してみましょう。特にLLM(大規模言語モデル)に適しており、AI全般にも適しています。具体的には以下を確認しています。

テキスト、画像、音声を共有された埋め込み空間に統一する
クロスモーダル埋め込みは、人工知能において画期的な進展をもたらし、統一された表現空間内で異なるデータタイプ間の理解と推論を可能にします。

予算のハードウェアでオープンモデルを使用して企業向けAIを展開
AIの民主化はここにあります。 Llama 3、Mixtral、QwenなどのオープンソースLLMが、今やプロプライエタリモデルと同等の性能を発揮するようになり、チームは消費者ハードウェアを使用して強力なAIインフラストラクチャを構築できるようになりました。これにより、コストを削減しながらも、データプライバシーやデプロイメントに関する完全なコントロールを維持することが可能です。

Docker Model Runnerでコンテキストサイズを設定する際の回避策
Docker Model Runnerにおけるコンテキストサイズの設定は、本来よりも複雑です。

テキスト指示を使って画像を拡張するためのAIモデル
ブラックフォレスト・ラボズは、FLUX.1-Kontext-devという高度な画像から画像へのAIモデルをリリースしました。このモデルは、テキストの指示を使って既存の画像を補強します。

NVIDIA CUDAをサポートしたDocker Model RunnerでGPU加速を有効にする
Docker Model Runner は、Dockerが公式に提供するローカルでAIモデルを実行するためのツールですが、
Docker Model RunnerにおけるNVidia GPUの加速の有効化 には特定の設定が必要です。

GPT-OSS 120bの3つのAIプラットフォームにおけるベンチマーク
私は、Ollama上でGPT-OSS 120bのパフォーマンステストを3つの異なるプラットフォームで確認しました:NVIDIA DGX Spark, Mac Studio, and RTX 4080。OllamaライブラリのGPT-OSS 120bモデルは65GBあり、これはRTX 4080(または新しいRTX 5080の16GB VRAMには収まらないことを意味します。

Docker Model Runner コマンドのクイックリファレンス
Docker Model Runner (DMR) は、2025年4月に導入された Docker の公式ソリューションで、AIモデルをローカルで実行するためのものです。このチートシートでは、すべての必須コマンド、構成、およびベストプラクティスのクイックリファレンスを提供しています。

Docker Model RunnerとOllamaを比較してみる:ローカルLLM向け
ローカルで大規模言語モデル(LLM)を実行する は、プライバシー、コスト管理、オフライン機能のためにますます人気になってきています。 2025年4月にDockerが**Docker Model Runner (DMR)**を導入し、AIモデルの展開用の公式ソリューションとして登場したことで、状況は大きく変わりました。

在庫状況、6か国の実際の小売価格、およびMac Studioとの比較。
NVIDIA DGX Spark は現実のものであり、2025年10月15日に販売開始され、CUDA開発者向けに、統合されたNVIDIA AIスタックを使用してローカルLLM作業を行う必要がある人を対象としています。US MSRPは**$3,999**; UK/DE/JPの小売価格はVATとチャネルの影響で高くなっています。AUD/KRWの公開価格はまだ広く掲載されていません。

AIに最適な消費者向けGPUの価格 - RTX 5080およびRTX 5090
またまた、LLM(大規模言語モデル)に特に、AI全般に適した上位レベルの消費者向けGPUの価格を比較してみましょう。具体的には、以下を確認しています。
RTX-5080およびRTX-5090の価格
価格はわずかに下がっています。
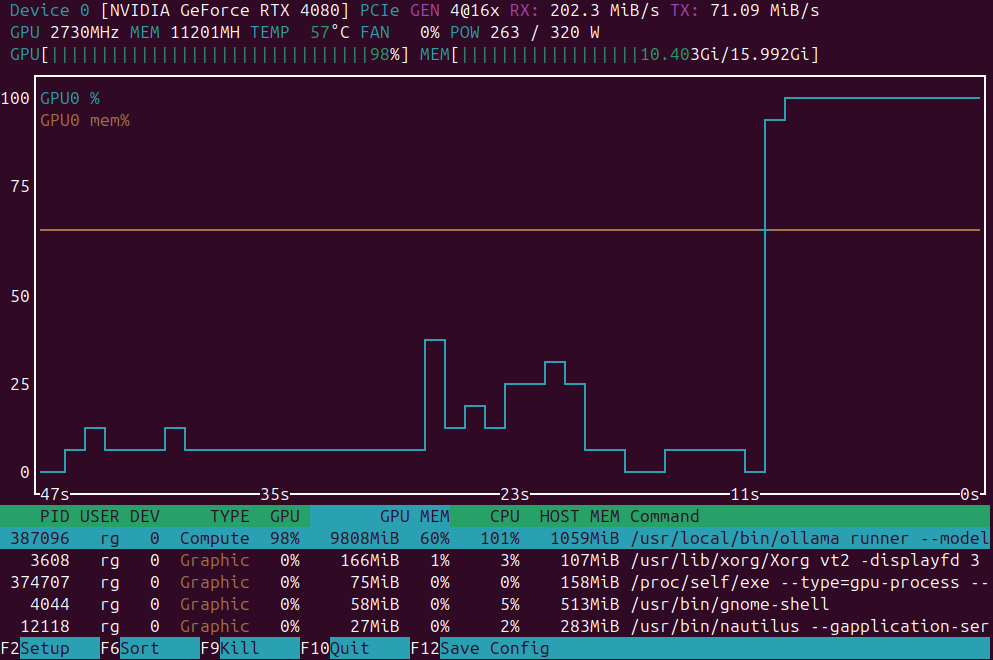
GPU負荷監視用のアプリケーションの簡単な一覧
GPU負荷監視アプリケーション: nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.

2025年7月にはすぐに利用可能になるはずです。
NVIDIAは、NVIDIA DGX Sparkを近日中にリリースする予定です。これは、ブラックウェルアーキテクチャを採用し、128GB以上の統合RAMと1 PFLOPSのAI性能を備えた小型のAIスーパーコンピュータです。LLMを実行するための非常に便利なデバイスです。