

LLM ASICの台頭:推論ハードウェアがなぜ重要なのか
専用チップにより、AIの推論がより高速かつ低コストになっている。
専用チップにより、AIの推論がより高速かつ低コストになっている。

在庫状況、6か国の実際の小売価格、およびMac Studioとの比較。
NVIDIA DGX Spark は現実のものであり、2025年10月15日に販売開始され、CUDA開発者向けに、統合されたNVIDIA AIスタックを使用してローカルLLM作業を行う必要がある人を対象としています。US MSRPは**$3,999**; UK/DE/JPの小売価格はVATとチャネルの影響で高くなっています。AUD/KRWの公開価格はまだ広く掲載されていません。

OllamaをGoで統合する: SDKガイド、例、およびプロダクションでのベストプラクティス
このガイドでは、利用可能な Go SDK for Ollama の包括的な概要を提供し、それらの機能セットを比較します。

これらの2つのモデルの速度、パラメータ、および性能の比較
ここに Qwen3:30b と GPT-OSS:20b の比較を示します。指示の遵守とパフォーマンスのパラメータ、仕様、速度に焦点を当てています。

あまり良くない。
OllamaのGPT-OSSモデルは、LangChainやOpenAI SDK、vllmなどのフレームワークと使用する際に、構造化された出力を処理する際に繰り返し問題が発生しています。

Ollamaから構造化された出力を得るいくつかの方法
大規模言語モデル(LLM) は強力ですが、実運用では自由な形式の段落はほとんど使いません。 代わりに、予測可能なデータ:属性、事実、またはアプリにフィードできる構造化されたオブジェクトを望みます。 それはLLM構造化出力です。

オラマモデルのスケジューリングに関する自分のテスト
ここでは、新しいバージョンのOllamaがモデルに対してどのくらいのVRAMを割り当てているかについて、Ollama VRAM割り当てと以前のOllamaバージョンを比較しています。新しいバージョンは、以前のバージョンよりも劣っています。

現在のOllama開発状況に対する私の見解
Ollama は、LLM をローカルで実行するためのツールとして、非常に人気のあるツールの一つとなっています。
シンプルな CLI と、モデル管理の簡素化により、クラウド外で AI モデルと仕事をしたい開発者にとっての定番のオプションとなっています。

2025年のOllamaで最も注目されているUIの概要
ローカルにホストされた Ollama は、あなたのマシン上で大規模言語モデルを実行できるが、コマンドライン経由での使用はユーザーにとって使いにくい。
以下に、ローカルの Ollama に接続するための、いくつかのオープンソースプロジェクトが提供する ChatGPTスタイルのインターフェース がある。
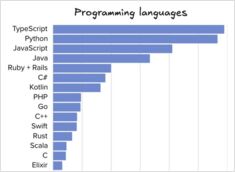
ソフトウェアエンジニアリングツールおよび言語の比較
The Pragmatic Engineerのレターは数日前に、2025年中盤におけるプログラミング言語、IDE、AIツールの普及状況などのデータを掲載しました。

2025年7月にはすぐに利用可能になるはずです。
NVIDIAは、NVIDIA DGX Sparkを近日中にリリースする予定です。これは、ブラックウェルアーキテクチャを採用し、128GB以上の統合RAMと1 PFLOPSのAI性能を備えた小型のAIスーパーコンピュータです。LLMを実行するための非常に便利なデバイスです。

RAGを実装中ですか?ここにGoのコードの一部 - 2...
標準的な Ollama には直接のリランク API がありませんので、 クエリとドキュメントのペアに対して埋め込みを生成し、それらをスコアリングすることで、Qwen3 リランカーを使用したリランキング(GO 言語で) を実装する必要があります。

以前、オブジェクト検出AIのトレーニングを行いました。
ある寒い冬の7月の日… その日はオーストラリアにいた… 私は、未封のコンクリート補強筋を検出するためのAIモデルを訓練するという緊急の必要性を感じた…

Qwen3 8B、14Bおよび30B、Devstral 24B、Mistral Small 24B
このテストでは、Ollama上でホストされているさまざまなLLMがHugoページを英語からドイツ語に翻訳する方法を比較しています。英語からドイツ語への翻訳。

RAGを実装中ですか?Golangでのコードスニペットの例をいくつか紹介します。
この小さな Reranking Goコード例はOllamaを呼び出して埋め込みを生成しています クエリと各候補ドキュメントに対して、 その後、コサイン類似度で降順にソートします。

LLM用に2番目のGPUをインストールすることを考慮していますか?
PCIe レーンがLLM性能に与える影響? タスクによります。トレーニングやマルチGPUの推論では、パフォーマンスの低下が顕著です。