

消費者向けハードウェア上の AI インフラ
オープンモデルを活用して、予算内のハードウェアでエンタープライズAIをデプロイする
AI の民主化はここにやってきました。 Llama、Mistral、Qwen などのオープンソース大規模言語モデル(LLM)が現在、プロプライエタリなモデルと競合するレベルに達しており、チームは 消費级ハードウェアを使用した AI インフラストラクチャ を構築することで、コストを削減しながらもデータプライバシーとデプロイの完全な制御を維持することが可能になりました。
オープンモデルを活用して、予算内のハードウェアでエンタープライズAIをデプロイする
AI の民主化はここにやってきました。 Llama、Mistral、Qwen などのオープンソース大規模言語モデル(LLM)が現在、プロプライエタリなモデルと競合するレベルに達しており、チームは 消費级ハードウェアを使用した AI インフラストラクチャ を構築することで、コストを削減しながらもデータプライバシーとデプロイの完全な制御を維持することが可能になりました。

プロメテウスで堅牢なインフラストラクチャのモニタリングを構築しましょう
Prometheus は、クラウドネイティブなアプリケーションとインフラストラクチャのモニタリングにおいて事実上の標準となり、メトリクスの収集、クエリ、可視化ツールとの統合を提供しています。
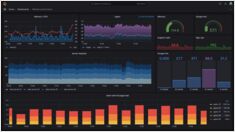
グラファナの設定をマスターしてモニタリングと可視化を実現しましょう
Grafana は、メトリクス、ログ、トレースを視覚的に表現し、アクション可能なインサイトに変換するための、監視および観測性のための主要なオープンソースプラットフォームです。

順序付きスケーリングと永続的なデータを使用してステートフルなアプリを展開する
Kubernetes StatefulSets は、安定したアイデンティティ、永続的なストレージ、および順序付きデプロイメントパターンを必要とするステートフルなアプリケーションを管理するための最適なソリューションです。データベース、分散システム、キャッシュレイヤーなどに不可欠です。

GGUF量子化でFLUX.1-devを高速化
FLUX.1-dev は、驚くほど美しい画像を生成できる強力なテキストから画像生成モデルですが、24GB以上のメモリが必要なため、多くのシステムでは実行が難しいです。 GGUF量化されたFLUX.1-dev は、メモリ使用量を約50%削減しながらも、優れた画像品質を維持するという解決策を提供します。

Docker Model Runnerでコンテキストサイズを設定する際の回避策
Docker Model Runnerにおけるコンテキストサイズの設定は、本来よりも複雑です。

テキスト指示を使って画像を拡張するためのAIモデル
ブラックフォレスト・ラボズは、FLUX.1-Kontext-devという高度な画像から画像へのAIモデルをリリースしました。このモデルは、テキストの指示を使って既存の画像を補強します。

NVIDIA CUDAをサポートしたDocker Model RunnerでGPU加速を有効にする
Docker Model Runner は、Dockerが公式に提供するローカルでAIモデルを実行するためのツールですが、
Docker Model RunnerにおけるNVidia GPUの加速の有効化 には特定の設定が必要です。

ヘッドレスCMSの比較 - 機能、パフォーマンスおよびユースケース
正しい ヘッドレス CMS の選択は、コンテンツ管理戦略を成功させるか、失敗させるかを左右します。 開発者がコンテンツ駆動型アプリケーションを構築する方法に影響を与える3つのオープンソースソリューションを比較してみましょう。

ご自身でホストするAIを活用したバックアップに使用される写真
Immich は、あなたの思い出を完全にコントロールできる、革新的なオープンソースでセルフホスト型の写真および動画管理ソリューションです。Google Photos と競合する機能を備えており、AI による顔認識、スマート検索、自動モバイルバックアップを含みながら、あなたのデータをプライバシーとセキュリティを保ったまま、あなたのサーバー上に保管します。

検索、インデックス作成、および分析のための Elasticsearch コマンド
Elasticsearch は、Apache Lucene を基盤に構築された強力な分散型検索および分析エンジンです。 この包括的なチートシートでは、Elasticsearch クラスターを操作するための重要なコマンド、ベストプラクティス、およびクイックリファレンスを取り上げています。

GPT-OSS 120bの3つのAIプラットフォームにおけるベンチマーク
私は、Ollama上でGPT-OSS 120bのパフォーマンステストを3つの異なるプラットフォームで確認しました:NVIDIA DGX Spark, Mac Studio, and RTX 4080。OllamaライブラリのGPT-OSS 120bモデルは65GBあり、これはRTX 4080(または新しいRTX 5080の16GB VRAMには収まらないことを意味します。

Docker Model Runner コマンドのクイックリファレンス
Docker Model Runner (DMR) は、2025年4月に導入された Docker の公式ソリューションで、AIモデルをローカルで実行するためのものです。このチートシートでは、すべての必須コマンド、構成、およびベストプラクティスのクイックリファレンスを提供しています。

Docker Model RunnerとOllamaを比較してみる:ローカルLLM向け
ローカルで大規模言語モデル(LLM)を実行する は、プライバシー、コスト管理、オフライン機能のためにますます人気になってきています。 2025年4月にDockerが**Docker Model Runner (DMR)**を導入し、AIモデルの展開用の公式ソリューションとして登場したことで、状況は大きく変わりました。
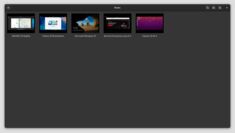
GNOME Boxes による Linux 用のシンプルな仮想マシン管理
現代のコンピューティング環境において、仮想化は開発、テスト、複数のオペレーティングシステムの実行において不可欠となっています。Linuxユーザーが仮想マシンを簡単に管理できる方法を探している場合、GNOME Boxesは、機能性を犠牲にすることなく、軽量で使いやすいオプションとして際立っています。
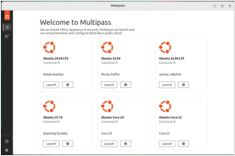
マルチパスのインストール、設定、および基本的なコマンド
Multipass は、Linux、Windows、macOS で Ubuntu クラウドインスタンスを作成および管理するのに役立つ軽量な仮想マシンマネージャです。